
Formação de Empresas Virtuais com Agentes Inteligentes
António
Manuel Correia Pereira
Dissertação
apresentada à Faculdade de Engenharia da Universidade do Porto para a obtenção
do grau de mestre em Inteligência Artificial e Computação
Trabalho realizado sob a
supervisão do
Professor Doutor Eugénio
Costa Oliveira
do
Departamento de Engenharia Electrotécnica e de Computadores
da
Faculdade de Engenharia da Universidade do Porto
Porto, Novembro de 2000
Em
memória do meu pai
“A
perfeição é atingida, não quando não há mais nada a acrescentar,
mas
quando não há mais nada a retirar”
Antoine de Saint-Exupèry
Agradecimentos
A escrita de uma tese apresenta uma oportunidade para agradecermos a todas as pessoas que, de uma forma ou de outra, participam na nossa vida e nos dão alento, empurrões e razões de viver.
Quero agradecer, em primeiro lugar, ao meu orientador Professor Doutor Eugénio Oliveira toda a disponibilidade manifestada e todos os ensinamentos científicos e de rigor com que me foi inundando ao longo destes meses. Fica, sem dúvida, entre nós um elo de amizade que perdurará, por certo, pela vida fora.
Também quero agradecer ao NIAD&R (Núcleo de Inteligência Artificial Distribuída e Robótica) o ambiente franco e descontraído com que me adoptou no seu seio, nomeadamente o Luís Paulo, a Ana Paula, a Conceição, a Célia, o Henrique e a Benedita. A minha gratidão muito especial ao Pedro Silva e ao Pedro Faria, amigos e companheiros de jornada. Sem todos vocês a minha tese não existiria.
Mais complicado de agradecer é àqueles que nos estão próximos e a quem nos unem laços familiares e de amizade.
À minha mãe Lucinda e ao meu pai Joaquim (in memoriam) – vocês foram o princípio de tudo. Obrigado.
À Graça, minha esposa, e às minhas filhas Patrícia e Filipa – o vosso amor, dedicação e confiança são o meu alento no dia-a-dia e ajudam-me a ultrapassar todos os obstáculos. Obrigado.
À minha sogra, Gracinda, que com a sua força me fez acreditar que iria conseguir – como ela diz: “O rabo é o mais difícil de esfolar”. Obrigado.
Aos meus familiares e amigos, com quem partilho os meus sonhos, alegrias, receios e preocupações. Obrigado por existirem.
O meu reconhecimento, também, à EFACEC Sistemas de Electrónica por me ter deixado entrar neste projecto e me ter apoiado, em disponibilidade, na sua concretização – em especial ao Carrapatoso que, por me considerar obsoleto, foi a mola real desta aventura.
Resumo
Actualmente as organizações são confrontadas com mercados em permanente mudança, competição global e ciclos de inovação tecnológica cada vez mais curtos. Com a generalização da Internet e a proliferação de mercados electrónicos, a capacidade de uma empresa em conseguir vantagem competitiva, e sobreviver em mercado tão dinâmico, depende da sua flexibilidade organizacional, disponibilidade de informação, coordenação efectiva das decisões e acções e alianças permanentes ou esporádicas com outras empresas que se disponham a enfrentar novas oportunidades de negócio.
Neste trabalho são descritos os requisitos para a negociação multi-critério e multi-atributo, com inclusão de restrições, necessária à formação automática de uma empresa virtual e é proposta a respectiva plataforma computacional – o sistema VESM (Virtual Enterprises Space Market).
As empresas envolvidas na negociação são representadas por agentes computacionais com capacidade para planear e coordenar as suas acções de um modo flexível e dinâmico, orientadas por objectivos, enquanto resolve problemas autonomamente de acordo com uma perspectiva local. Estes agentes reflectem as decisões distribuídas e a execução de processos das empresas modernas na sua maior extensão. Modelando a formação de uma empresa virtual como um problema de decisão distribuído que requer a coordenação de entidades autónomas, os sistemas multi-agente permitem a realização desse objectivo em cenários sofisticados e realistas.
A plataforma apresentada contrasta com algumas arquitecturas tradicionais baseadas em pedidos a intermediários (request-brokers) pois estes necessitam de grandes esforços de normalização para serem aplicáveis.
São abordadas duas formas de considerar o problema da negociação baseadas na descrição do produto ou serviço – descrição qualitativa e descrição quantitativa. Com o protótipo desenvolvido podem mesmo ser combinadas as duas descrições e ter um produto dividido em subprodutos onde alguns se descrevem quantitativamente e outros se descrevem qualitativamente. Mesmo a propagação das restrições e a consequente negociação para resolução de conflitos pode utilizar as duas descrições simultaneamente.
O trabalho apresenta uma arquitectura base para a negociação num mercado electrónico entre consumidor e possíveis fornecedores. A plataforma Jini e o seu serviço JavaSpaces funcionam como plataforma distribuída de comunicação sobre a qual foi construído o sistema VESM.
Abstract
Nowadays
organizations are facing continuously changing markets, global competition and
shorter technological innovation cycles. Following the generalization of the
Internet use and the increasing number of electronic markets, the ability of
one enterprise to get advantage over competitors, and to survive in such
dynamic markets, depends on its organizational flexibility, information
availability, effective coordination of decisions and actions and permanent or
spurious alliances with other enterprises that are also engaged to get new
market opportunities.
In this
work the requirements for multi-criteria and multi-issue negotiation, including
constraints satisfaction, important for the formation of a virtual enterprise
are presented, an appropriate computational platform is proposed– the Virtual
Enterprises Space Market (VESM) system.
Enterprises
involved in the negotiation are represented through agents including planning
and coordination capabilities suitable for solving problems autonomously,
guided by goals, and also according to their local perspectives. These agents
reflect the distributed decision-making and processes execution that modern
organizations often face. By modeling the formation of a virtual enterprise as
a distributed decision problem, that requires coordination of autonomous
entities, the Multi-Agent Systems enable us to achieve that goal (distributed
decision-making with autonomy) in sophisticated and realistic scenarios.
The
platform we here introduce, is in contrast with traditional architectures that
are based on a request-broker scheme that would need huge standardization
efforts to be applicable to virtual enterprises.
Two
possibilities for the negotiation process are presented here that are based on
the product, or service, descriptions – both qualitative and quantitative
descriptions. With the developed prototype, both descriptions can be mixed and
making it possible to have a product description divided into sub-products
where some are described in a quantitative way and the others are described in
a qualitative way. Also the constraint propagation process, as well as the
subsequent negotiation for conflict resolution, can use both descriptions.
This work
presents an architecture for the negotiation in an electronic market between a
client and several possible suppliers. The Jini platform and its JavaSpaces
service has been used as a distributed communication platform over which the
VESM system was built.
Resumé
Actuellement les
organisations sont confrontées avec des marchés en permanent changement,
compétition globale et cycles d’innovation de plus en plus courts. Avec la
généralisation de l’Internet et la prolifération des marchés électroniques,
l’habilité d’une entreprise pour avoir l’avantage compétitif, survivre dans ce
type de marché dynamique, ça dépend de sa propre flexibilité organisationnelle,
de la coordination de ses décisions et actions, et aussi de ses alliances
permanentes ou casuelles avec des autres entreprises qui sont disposés à faire
face à nouvelles opportunités de commerce.
Ce travail décrie
les réquisits pour la négotiation multi-critérium et multi-attribut, en
utilisant des restrictions, pour la formation d’une entreprise virtuelle. Une
plate-forme computacionelle a été proposé pour l’exécution – le système VESM (Virtual Enterprises
Space Market).
Les entreprises
engagées dans la negotiation sont représentés par des agents capables de
concevoir et coordonner leurs actions de façon flexible et dynamique, orientés
par objets, en même temps qu’ils résoudrent des problèmes autonomement, suivant
une perspective locale. Ces agents reflètent les décisions distribuées, et
l’exécution des procédés des entreprises modernes. La modélisation de la formation
de l’entreprise virtuelle comme un problème de décision distribué qui oblige la
coordination d’entités autonomes, est réalisé, dans une scène complexe et réel,
avec les systèmes multi-agent.
La plate-forme
présenté est différente des architectures traditionnelles ou les demandes sont
faites à un intermédiaire (request-broker).
En ce cas là, les intermédiaires ont besoin d’un gros effort de normalisation
pour être applicable.
Nous introduisons
deux façon différents de considérer le problème de la négotiation – la
description qualitative et la description quantitative du produit ou service.
Avec le prototype développé c’est possible de réunir les deux descriptions et
obtenir la description d’un produit séparé en sub-produits où quelques-uns sont
décrits quantitativement et les autres sont décris qualitativement. Le
processus de la propagation des restrictions et de la résolution des conflits
peuvent aussi utiliser ces mêmes descriptions.
Ce travail
présente une architecture computationelle pour la négotiation entre un
consommateur et plusieurs possibles fournisseurs dans un marché électronique.
La plate-forme Jini et son service JavaSpaces sont utilisées comme une
plate-forme distribuée de communication sur la quelle le système VESM a été
construit.
Índice de Conteúdos
2.1 Conceito de Empresa
Virtual
2.1.1 O
que significa Virtual?
2.1.2 Definições
e Características de Empresas Virtuais
2.1.3 Topologia
de Empresa Virtual
2.2.1 TOVE (TOronto Virtual Enterprises)
2.2.2 CIM-OSA (Computer-Integrated Manufacturing – Open-Systems Architecture)
2.2.3 PERA
(Purdue Enterprise Reference Architecture)
2.2.5 ARTOR
(Artificial Organizations)
2.3 Arquitecturas de
Informação de Empresas
2.4 Infra-estruturas para
Empresas Virtuais
2.4.1 Definição
de Empresa Virtual
2.4.2 Terminologia
relacionada
2.4.3 Classificação
de Empresa Virtual
2.4.5 Participantes
da Empresa Virtual
3 Projecto de um Sistema Multi-Agente
para a Formação de uma Empresa Virtual
3.2 Estrutura do Sistema
Multi-Agente
3.2.1 Arquitectura
dos Agentes
3.2.2 Descrição
Formal dos Objectivos da Empresa Virtual
3.3 Estrutura de contratação
no mercado (negociação)
3.3.3 Formulação
das propostas
3.3.4 Resolução
do problema da satisfação das restrições
4.1.2 Arquitectura
de Segurança
4.1.3 RMI (Remote Method Invocation)
4.2.6 Diferenças
entre Jini e RMI
4.2.7 Diferenças
entre Jini e CORBA
4.3.1 Desafios
da Computação Distribuída
4.3.2 JavaSpaces
– Um Novo Modelo de Computação Distribuída
4.4.2 Configurações
necessárias
5 Conclusões e trabalho futuro
Índice de Figuras
Figura 2 - Camadas de
uma ontologia TOVE
Figura 4 - Agente de
Informação (Barbuceanu e Fox)
Figura 5 – Ciclo de
vida de uma EV (Camarinha-Matos e Afsarmanesh)
Figura 7 - Arquitectura
do agente empresa
Figura 8 - Arquitectura
do agente utilizador
Figura 9 - Protocolo de
Negociação
Figura 10 - Protocolo
para resolução da satisfação das restrições
Figura 11 - Modelo de
Segurança Java 1.0
Figura 12 - Modelo de
Segurança Java 1.1
Figura 13 - Modelo de
Segurança Java 1.2
Figura 14 - Utilização
do RMI registry
Figura 15 - Protocolo Discovery
Figura 18 - Cliente usa
o serviço
Figura 19 - Processos
usam o espaço e operações simples
para coordenar as suas actividades
1 Introdução
1.1 Motivação
Este trabalho sobre “Formação de Empresas Virtuais com Agentes Inteligentes” equaciona dois temas de grande importância. De facto, embora inicialmente a minha motivação fosse o estudo e desenvolvimento de Agentes Inteligentes, rapidamente percebi que a investigação sobre as empresas virtuais é um campo muito mais vasto e atraente do que inicialmente imaginei. Talvez o facto de a minha vida profissional ser passada numa empresa real torne mais aliciante a investigação em torno das empresas virtuais – porque a empresa virtual é pensada à volta do que as empresas reais têm de melhor para oferecer e funcionar e tenta subalternizar os seus vícios de funcionamento.
Também os trabalhos de investigação de Rocha e Oliveira sobre a formação de empresas virtuais, a decorrer no Núcleo de Inteligência Artificial Distribuída e Robótica (NIAD&R), foram uma das fontes de inspiração deste projecto.
As novas tendências de mercado derivadas da globalização da economia, a formação de grandes espaços económicos, os ciclos de inovação cada vez mais curtos, o mercado cada vez mais agressivo e dinâmico e o crescimento acentuado de segmentos de mercado especializados obrigam a novas formas de pensamento económico, forçando as empresas a cooperarem, muitas vezes com os seus mais directos competidores.
Hoje em dia são poucas as empresas que fabricam um produto integralmente. As empresas reduzem a sua actividade às competências técnicas base e unem esforços com outras empresas para fornecer novos produtos e serviços que o mercado exige. Nesta perspectiva uma empresa é apenas um nó que acrescenta valor a uma rede produtiva. Esta organização de empresas tem existência prática na indústria automóvel há muitos anos, mas neste momento tem tendência a espalhar-se a novas áreas de actividade. A materialização deste modelo de organização e cooperação entre empresas do futuro dá origem às chamadas empresas virtuais.
A empresa virtual será uma rede temporária de empresas independentes, com diferentes funções e atribuições, ligadas por uma rede de comunicações, e que partilham competências técnicas para aceder a novos mercados. A empresa virtual apenas existe durante um período de tempo limitado, o período de tempo necessário para satisfazer o objectivo a que se propõe.
O ciclo de vida de uma empresa virtual (EV), utilizado neste trabalho, é decomposto em quatro fases [FIS96]:
· identificação das necessidades: descrição do produto ou serviço a ser fornecido pela EV;
· formação: selecção dos parceiros que farão parte da EV baseada nos conhecimentos, competências, capacidade, recursos, custos e disponibilidade;
· operação: controlo e monitorização dos processos dos parceiros, incluindo resolução de conflitos e possível reconfiguração da EV se um dos parceiros falhar;
· dissolução: finalização da EV, distribuição de lucros e registo de informação relevante.
1.2 Objectivo
O âmbito deste trabalho está focado na fase da formação da empresa virtual. Durante o processo de formação a empresa virtual é modelada como um sistema multi-agente onde os agentes individuais (que representam as várias empresas) são unidades inteligentes, heterogéneas e com algum grau de autonomia que se conhecem num Mercado Electrónico.
Pretende-se que o processo de formação da empresa virtual seja automático e obrigado a passar pelos seguintes estados:
· descrição no mercado electrónico dos objectivos da empresa virtual – serviços a satisfazer ou produtos a fornecer (resultado da fase de identificação de necessidades);
· apresentação das propostas das empresas potenciais interessadas;
· selecção dos parceiros que participarão na empresa virtual através da negociação.
O seu objectivo principal é estudar métodos possíveis de implementação que permitam incluir restrições em negociação entre agentes na formação de empresas virtuais. Os serviços negociados não sendo independentes entre si podem propagar restrições mútuas.
Durante o processo da formação da EV, os objectivos da futura EV devem ser descritos de uma forma precisa e estar acessíveis a todas as empresas que, estando no mercado, pretendem agarrar qualquer oportunidade de negócio que lhes surja. A descrição dos bens (produtos ou serviços) a fornecer deve ser caracterizada de uma forma precisa, sem dar azo a ambiguidades. As condições impostas para a negociação desses mesmos bens também devem ser precisas e facilmente identificáveis.
No próprio objectivo estão indicadas as metodologias a utilizar no trabalho – sistema multi-agente da área da Inteligência Artificial Distribuída. Cada empresa, ou parte de empresa, será representada por um agente a quem foi conferida determinada autonomia e autoridade para tomar decisões em nome do seu representante (empresa).
Neste trabalho são analisadas duas formas de descrever os produtos ou serviços (descrição quantitativa e descrição qualitativa) e efectuada a sua comparação.
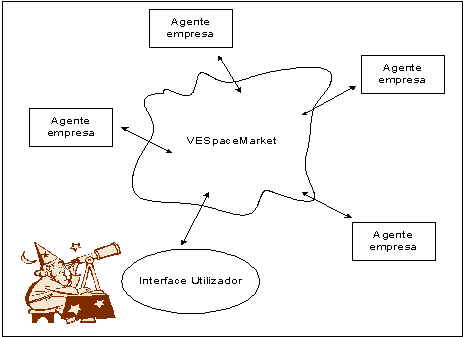
Foi desenvolvida uma plataforma computacional que permite a criação de agentes empresa que se encontram num mercado electrónico para negociar possíveis acordos de fornecimento de serviços. A plataforma corre numa Java Virtual Machine (JVM) e assenta num sistema Jini [ARN99] com o serviço JavaSpaces [FRE99] activo e que permite obter um sistema distribuído de comunicações sobre o qual foi construído o sistema VESM (Virtual Enterprises Space Market). Ao mercado elctrónico foi dado o nome VESpaceMarket. Qualquer empresa (agente) necessita apenas de saber o nome do mercado, e ligar-se a ele, para ser automaticamente candidata a membro de uma EV. Neste espaço as mensagens entre os agentes são encarnadas como classes Java, suprimindo desde logo problemas de sintaxe que possam ocorrer. As classes Java utilizadas para a comunicação utilizam interfaces Java bem conhecidas e evitam o parsing das mensagens, processamento sempre um pouco delicado, facilitando o encontro das empresas no mercado.
Cada agente é, do ponto de vista computacional, um thread de execução que pode ser lançado em qualquer altura por um agente de interface ao utilizador que permite visualizar o mercado e as empresas que o integram. Este agente pode ainda caracterizar as empresas e observar os processos de negociação e de resolução de conflitos por propagação de restrições.
1.3 Estrutura da tese
Neste capítulo é efectuada a apresentação genérica da motivação e dos objectivos que conduziram à realização deste trabalho. É também apresentada, de forma detalhada, a definição do problema que originou a tese.
No capítulo 2 é realizada uma revisão ao estado da arte no domínio das Empresas Virtuais e são referidos alguns projectos em curso.
No capítulo 3 é descrito o projecto do sistema desenvolvido e que suporta o trabalho de tese, com a apresentação da arquitectura idealizada e das metodologias envolvidas.
No capítulo 4 é descrita a implementação do sistema projectado e da tecnologia que o suporta.
No capítulo 5 são apresentadas as conclusões e apontadas algumas ideias para trabalhos futuros nesta área.
2 Empresas Virtuais
A área de investigação das empresas virtuais é demasiado vasta para ser reduzida a uma simples discussão de tecnologia. A inter-disciplinaridade do tema obriga a envolver um grande número de ciências para se conseguir abordar todas as franjas das EVs - engenharia, comunicações, computadores, economia, direito, gestão de empresas, sociologia.
O primeiro problema que surge quando se começa a investigação desta nova forma de organizações (as EVs) é a própria definição de empresa virtual. A maior parte dos autores utiliza a sua própria definição de EV. Cada definição tem as suas próprias características e é possível, quando comparadas, encontrar definições que se sobrepõem mas, também, algumas contradições.
O segundo problema que se coloca, mais difícil de resolver, está relacionado com a representação computacional da empresa virtual e das empresas que a constituem – para ser possível participar numa negociação automática e, possivelmente, integrar uma EV, cada empresa individual deve ter um modelo computacional capaz de a representar em todas as fases do ciclo de vida da EV.
Estando resolvidos estes problemas outros surgem como: troca de informações, comunicações seguras, gestão integrada do projecto, fiscalização da actuação dos membros da EV, garantia de qualidade do produto criado, confiança na informação fornecida pelas empresas, etc.
Finalmente as linguagens de comunicação e as ontolgias associadas também colocam alguns obstáculos, muitas vezes difíceis de resolver.
2.1 Conceito de Empresa Virtual
O trabalho de Bultje e van Wijt “Taxinomia de Organizações Virtuais baseada nas Definições, Características e Topologia” [BUL98] apresenta um estudo interessante sobre o tema e pretende clarificar o conceito de empresa virtual, ou organização virtual.
2.1.1 O que significa Virtual?
As diferenças encontradas começam logo na definição do que significa virtual:
· Virtual pode significar “não real, parecido com o real”. Esta definição, originada da Óptica, distingue entre imagem real e imagem virtual – ambas as imagens parecem a mesma mas a imagem virtual não pode ser fotografada, ao contrário da imagem real. [AKEN98].
· Virtual pode significar “imaterial, suportado pelas tecnologias de informação (TI)”. O conceito de virtual é usado em expressões como biblioteca virtual, sala de aula virtual. As funções desempenhadas normalmente por pessoas são substituídas pelas tecnologias de informação e comunicações [AKEN98].
· Virtual pode significar “potencialmente presente”. A EV apenas existe se uma oportunidade para tal aparecer. Enquanto tal não acontecer a EV está inactiva [JÄGE98].
· Virtual pode significar “existente mas em mutação”. A EV existe mas a sua composição é temporária e pode ser alterada a cada momento.
Qualquer destes significados de virtual pode ser, também, encontrado em definições de EV.
2.1.2 Definições e Características de Empresas Virtuais
Segundo van Aken [AKEN98] “uma Organização Virtual é uma rede de organizações, estruturada e gerida de tal forma que aparece aos clientes e fornecedores externos identificada como uma única empresa”. A ideia base desta definição é que uma EV é identificável como uma empresa única mas, de facto, é constituída por várias empresas. Esta definição engloba o primeiro conceito de virtual como sendo algo parecido com o real.
Na definição de Byrne [BYRN93] “uma Organização Virtual é uma rede temporária de empresas independentes unidas por tecnologias de informação que partilham competências técnicas, custos e acesso aos mercados de cada um. As empresas unem-se para explorar oportunidades de mercado específicas e, posteriormente, separam-se.” Esta definição é mais abrangente e engloba três das definições anteriores de virtual: imaterial, suportada pelas TI, potencialmente presente e existente mas em mutação. Potencialmente presente porque a cooperação apenas existe durante a oportunidade de mercado.
De acordo com Jansen, Steenbakkers e Jägers [JÄGE98] “uma Organização Virtual é uma combinação de várias partes (pessoas e/ou organizações) dispersas geograficamente, que partilham as suas competências e recursos com o intuito de alcançar um objectivo comum. Os parceiros desta OV têm igual estatuto e estão dependentes de ligações electrónicas (TI) para a coordenação das suas actividades”. A dependência das tecnologias de informação e comunicações é a principal característica deste tipo de EV.
Segundo Mowshowitz [MOWS94] “a essência das Organizações Virtuais é a metagestão da actividade de atingir objectivos de forma independente da sua realização. Metagestão é a gestão de uma actividade organizada virtualmente. Esta actividade organizada virtualmente contém um conjunto de requisitos, um conjunto de empresas que os podem satisfazer e uma tabela de procedimentos que mapeia as empresas nos requisitos”. Esta definição está relacionada com o modo como a EV é constituída. A sua composição é dependente dos requisitos da EV e de como as empresas podem satisfazer esses requisitos. Quando os requisitos mudam é provável que as empresas que os satisfazem também mudem – a última definição de virtual (existente mas em mutação) é a que melhor se aplica a este caso.
Para melhor entender as diferenças entre as quatro definições acima referidas, Bultje e van Wijt foram mais longe e procuraram as características das EVs distribuídas pela literatura existente. Nesta investigação encontraram nada menos do que vinte e sete características diferentes para as EVs. Destas, existem seis que, de acordo com os autores, são características chave de uma EV:
· Baseadas nas competências nucleares [JÄGE98] – Os parceiros apenas contribuem para a EV com as suas competências nucleares (mais fortes). A combinação de todas as competências nucleares une sinergias e permite, de um modo flexível, atingir as exigências dos consumidores. É possível atingir uma organização excelente, porque cada parceiro colabora com o que tem de melhor.
· Rede de organizações independentes [AKEN98] – A EV é um conjunto de empresas independentes ligadas por relações semi-estáveis.
· Uma identidade [AKEN98] – Cada EV deve ter a sua identidade própria. Além da identidade da EV, a identidade de cada parceiro deve ser mantida visível.
· Baseada nas tecnologias de informação [MOWS94], [BYRN93] e [JÄGE98] – As tecnologias de informação são o factor chave na expansão das EVs, bem como os progressos nos transportes, comunicações e computação. Para quase todos os autores as EVs assentam em tecnologias de informação baseadas em computadores.
· Sem hierarquia [SIEB98] – Não existe hierarquia numa EV devido à igualdade dos parceiros. Esta característica aumenta a eficiência e a reacção da EV e diminui os gastos.
· Separação entre os níveis estratégico e operacional [MOWS94] – Ao nível da gestão existe uma distinção clara entre os requisitos abstractos (estratégia global) e a implementação concreta para atingir os objectivos organizacionais (operação local). Evitam-se, assim, os problemas complexos de controlo.
Nas restantes características encontramos quase outra definição para EV: constituída por parceiros de pequena dimensão, geograficamente dispersos, unidos por uma rede dinâmica, que mantêm relações semi-estáveis baseadas na confiança e na partilha de propriedade, liderança, lealdade e riscos, sem estrutura de organização rígida, dirigida ao consumidor e dependente das oportunidades e da inovação.
Aliás, como conclusão, os autores chegam à seguinte definição funcional de EV:
Uma Empresa Virtual é composta por uma rede de empresas independentes, dispersas geograficamente com uma missão parcialmente sobreposta. Todos os parceiros da EV participam com as suas competências fundamentais e a cooperação é baseada em relações semi-estáveis. Os produtos e serviços fornecidos pela EV estão fortemente orientados para o utilizador final e muito dependentes das oportunidades de negócio e da inovação. A empresa virtual pode ainda ser caracterizada por ter uma identidade própria, por exigir lealdade entre os parceiros e cooperação baseada na confiança e nas tecnologias de informação e por manter uma distinção nítida entre os níveis operacional e estratégico.
2.1.3 Topologia de Empresa Virtual
O estudo de Bultje e van Wijt [BUL98] termina com a possível classificação das EV em quatro topologias:
- EV interna – Conceito aplicado a uma empresa constituída por várias unidades de negócio, cada uma com grupos e equipas autónomas. As tarefas de gestão são, normalmente, executadas de um modo descentralizado por cada uma das equipas. Os empregados estão distribuídos por vários locais de trabalho diferentes, razão que leva a adoptar este tipo de organização.
- EV estável – Conceito aplicado a um grupo de empresas cooperantes liderado por uma delas. As competências não elementares da empresa principal são atribuídas (contratadas) a uma das várias empresas fornecedoras do grupo.
· EV dinâmica – Baseada na cooperação aberta entre organizações. As relações entre as organizações são baseadas na oportunidade e sempre temporárias. Por isso a cooperação apenas acontece quando uma oportunidade de negócio aparece. Este tipo de empresa apresenta um grau muito elevado de flexibilidade. É tipicamente constituída por pequenas e médias empresas (PMEs) com igualdade de tratamento, onde não existe uma empresa principal e a liderança é partilhada.
· Empresa Web – Uma empresa Web, também conhecida como ‘empresa ágil’, é uma rede temporária de organizações especializadas que baseiam o seu negócio no uso da Internet. Pretende oferecer, via Internet, todo o tipo de produtos e serviços disponíveis via Internet. O bom funcionamento desta empresa dependente fortemente da gestão e partilha de conhecimento entre os parceiros cooperantes. É também, normalmente, constituída por PMEs e apresenta uma diferença fundamental em relação à EV dinâmica – é completamente baseada nas tecnologias de informação (TIs). Enquanto uma EV dinâmica pode existir sem TIs, uma empresa Web não.
Analisando mais atentamente cada uma das topologias apresentadas pode verificar-se que as EV dinâmicas e as empresas Internet são as que melhor encaixam na definição funcional de EV.
Uma das questões levantadas neste estudo é até que ponto uma EV interna ou uma EV estável podem ser consideradas EVs, visto que são empresas que existem independentemente das oportunidades de negócio, têm relações permanentes entre os seus membros e muitas delas têm uma empresa principal a coordenar a sua actividade.
2.2 Modelação de Empresas
O Laboratório de Integração de Empresas da Universidade de Toronto, Canadá (EIL – Enterprise Integration Laboratory), liderado pelo professor Mark S. Fox [EIL94], é sem dúvida, uma referência na área da modelação de empresas, através da introdução das ontologias TOVE (TOronto Virtual Enterprises)[TOV9x] e dos projectos de modelação de empresas CIM-OSA [THAM9xA] e PERA [THAM9xB], entre outros.
2.2.1 TOVE (TOronto Virtual Enterprises)
Um Modelo de Empresa é uma representação computacional da estrutura, processos, informação, recursos, objectivos e restrições de um negócio, actividade governamental ou outro sistema organizacional. Funciona simultaneamente como uma descrição e uma definição, aproximando o que deve ser e o que é. Deve ser facilmente adaptável em termos de operação, análise e projecto.
Existem quatro objectivos básicos no projecto de um Modelo de Empresa:
- Reutilização - relacionado com o alto custo de construir um modelo de dados de uma grande empresa – a existência de um modelo de empresa genérico e reutilizável reduz significativamente o custo de construir um sistema.
- Utilização Consistente do modelo – indicando o conjunto de aplicações possíveis do modelo, o seu conteúdo deve ser preciso e rigoroso de modo a ser possível utilizá-lo, de forma consistente, em toda a empresa.
- Acessibilidade – sendo necessário que pessoas e outros agentes acedam a informação relevante para as suas tarefas, o modelo deve ser definido para suportar processamento de queries.
- Selecção – escolher o modelo de empresa mais adequado para cada aplicação.
Para ser possível fazer a integração total de uma empresa em termos computacionais é necessário existir uma representação partilhada de conhecimento que minimize a ambiguidade e maximize a compreensão e a precisão da comunicação. Além disso, a criação de tal representação deve eliminar muita da programação requerida para responder às questões de “senso comum” sobre uma empresa. O objectivo do projecto TOVE [TOV9x] é criar um modelo de dados genérico e reutilizável com as seguintes características:
- Fornecer uma terminologia comum, partilhada para a empresa, que cada agente e aplicação possa facilmente compreender e utilizar;
- Definir o significado de cada termo (semântica) de uma forma precisa e sem ambiguidades, se possível utilizando lógica de 1ª ordem;
- Implementar a semântica num conjunto de axiomas que permitam, ao TOVE, deduzir automaticamente as respostas às perguntas de “senso comum” acerca da empresa;
- Definir uma simbologia para cada termo ou conceito poder ser construído num contexto gráfico.
A característica reutilizável do TOVE representa um avanço significativo nas ontologias de conceitos industriais.
Actualmente as ontologias TOVE (Figura 1) envolvem: actividades, estado, causalidade, tempos, recursos, inventário, ordens de compra, componentes, qualidade, custos baseados em actividade e estruturas organizacionais.
Cada uma das ontologias TOVE está estruturada em cinco camadas: teorias fundamentais, blocos de construção da ontologia, definições e bibliotecas de objectos das ontologias genéricas e modelos de empresa (Figura 2).
Apresentam-se, de seguida, duas metodologias de modelação de empresas relacionadas com as ontologias TOVE.
2.2.2
CIM-OSA
(Computer-Integrated
Manufacturing – Open-Systems Architecture)
O objectivo do CIM é a integração apropriada das operações de fabrico de uma empresa através de uma troca de informação eficiente, dentro da empresa, com a ajuda das tecnologias de informação. A arquitectura de sistemas abertos (OSA) define uma metodologia integrada para suportar todas as fases do ciclo de vida de um sistema CIM, desde a especificação dos requisitos, projecto de sistema, implementação, operação e manutenção e, até, migração do sistema com a solução CIM-OSA [THAM9xA].
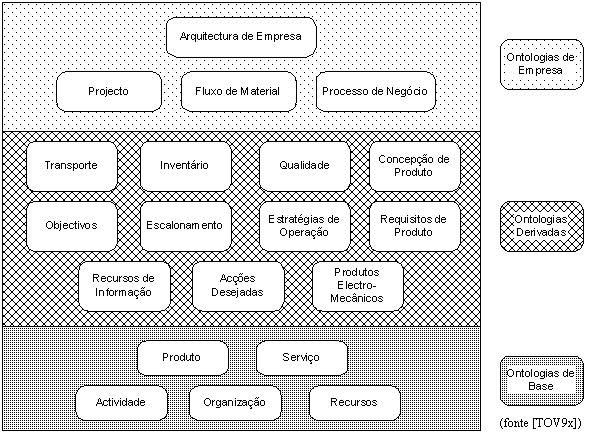

Figura 2 - Camadas de uma ontologia TOVE
CIM é um paradigma de produção desenvolvido na década de 80 e foi reconhecido como de importância estratégica para as indústrias europeias. O programa ESPRIT (European Strategic Programme for Research and Development in Information Technology) financiou vários projectos CIM. CIM-OSA é o resultado do projecto ESPRIT 688 com o nome de código AMICE, acrónimo invertido de European Computer Integrated Manufacturing Architectures.
O CIM-OSA [THAM9xA, BAS97] é uma arquitectura que descreve o mundo real de uma indústria ao fornecer um conjunto único de características avançadas para modelar a funcionalidade e o comportamento dos sistemas CIM a três níveis: definição de requisitos, especificação do projecto e descrição da implementação. Esta descrição é utilizada para controlar a operação da empresa e para planificar, projectar e optimizar actualizações ao ambiente de operação real.
Partindo de um conjunto finito, mas compreensível, de conceitos de modelação, uma empresa industrial pode criar um modelo preciso dos seus próprios requisitos CIM, utilizando um conjunto standard de construções básicas e modelos parciais e transformando estes modelos através de uma série de passos bem definidos até chegar ao modelo do sistema CIM físico que contém os requisitos. Garantindo que a implementação do modelo físico é directamente processada pelos componentes das tecnologias de informação do sistema, o controlo da operação do sistema CIM em funcionamento normal pode ser conseguido em consonância com o comportamento especificado da empresa. Da aplicação CIM-OSA resulta uma descrição completa da empresa, que é guardada e manipulada pelas tecnologias de informação da própria empresa.
A metodologia de modelação CIM-OSA é mais descritiva que prescritiva. Para poder satisfazer as necessidades de várias empresas, o CIM-OSA não define uma arquitectura standard a ser usada por toda a indústria mas uma Arquitectura de Referência, a partir da qual as arquitecturas particulares devem ser derivadas.
Os objectivos do projecto CIM-OSA são:
- apresentar uma arquitectura de referência para a construção de sistemas em CIM evitando a existência de "ilhas de automação";
- tornar-se um padrão aceite pelos fornecedores de produtos para CIM e seus utilizadores. Isto permite que a integração de componentes seja garantida a priori, se todos os componentes de um CIM forem desenvolvidos de acordo com o CIM-OSA.
O projecto CIM-OSA pretende fornecer facilidades para:
- desenvolver modelos empresariais de uma forma evolutiva através da modelação modular de uma empresa;
- definir, descrever e estruturar os requisitos de uma empresa de uma maneira consistente e significativa;
- derivar, a partir deste requisitos, o projecto do sistema e especificações relevantes dos componentes empresariais;
- possibilitar a manutenção do modelo empresarial (adaptação às mudanças externas e internas).
A abstracção, a modularidade e a separação entre os requisitos do utilizador e a implementação do sistema são alguns dos princípios arquitecturais utilizados pelo CIM-OSA. O processo de construção arquitectural do CIM-OSA guia o utilizador CIM, durante a fase de projecto, para obter uma descrição do sistema consistente com os requisitos do utilizador definidos, através dos níveis de modelação Definição de Requisitos, Especificação do Projecto e Descrição da Implementação, e considerando os aspectos funcionais, de informação e de recursos da organização.
2.2.3 PERA (Purdue Enterprise Reference Architecture)
O projecto PERA [THAM9xB], desenvolvido pelo Laboratório de Aplicações de Controlo Industrial da Universidade de Purdue, West Lafayette, teve início em Dezembro de 1990, e pretende encontrar uma representação capaz de incorporar funções novas, implementadas pelos utilizadores, num ambiente CIM já em funcionamento sem ter necessidade de interromper o sistema.
O modelar uma empresa CIM em três tipos de tarefas (Sistema de Informação, Fabrico/Produção e Operadores/Utilizadores) que se inter-relacionam, num sistema CIM implementado e em funcionamento, é a característica que distingue o projecto PERA dos restantes projectos de modelação de empresas existentes. Nas metodologias anteriores as funções humanas eram consideradas tipicamente como exteriores à modelação.
A assimilação do paradigma de modelação PERA resulta num modelo estruturado que pode ser aplicado a qualquer empresa, independentemente do tipo de indústria envolvido, e a sua aplicabilidade ultrapassa a descrição de um sistema CIM inicialmente projectada.
As descrições funcionais de tarefas e funções da empresa são divididas em 2 unidades:
- Unidade de Informação
- Unidade de Fabrico e Serviço de Clientes
Neste modelo as classes de funções envolvendo decisão, controlo e informação (manipulação de dados) estão concentradas na unidade funcional de Informação.
Durante a implementação as duas unidades funcionais são rearranjadas em três conjuntos de tarefas e funções:
- Actividades humanas relacionadas (i) com a informação e o controlo e (ii) com o fabrico e serviço a clientes.
- Actividades de informação não dependentes de humanos.
- Actividades de fabrico e apoio a clientes não desempenhadas por humanos.
A metodologia de modelação empresarial PERA tenta modelar uma empresa através da representação de três tarefas principais ou categorias:
- Tarefas ou Processos de Informação
- Tarefas ou Processos de Fabrico
- Tarefas ou Processos Humanos e de Organização
Através da categorização explícita e representação das tarefas ou processos humanos e de organização é estabelecida a base para o tratamento das funções implementadas por humanos numa empresa CIM.
2.2.4 HOLOS
O Instituto de Desenvolvimento de Novas Tecnologias (Uninova) [UNI86] da Faculdade de Ciências e Tecnologias da Universidade Nova de Lisboa, liderado pelo professor Luís M. Camarinha-Matos, tem desenvolvido trabalhos na área da arquitectura de sistemas modelados para escalonamento dinâmico de recursos de produção em organizações virtuais.
A arquitectura de sistema HOLOS [RAB96] foi projectada para permitir escalonamento dinâmico e adaptação fácil num processo de fabrico que envolve, tipicamente, várias empresas ligadas por tecnologias de informação. O sistema HOLOS é suportado por 3 elementos:
Integração de Informação e Modelação - é utilizado um sistema de informação CIM para integrar as diversas actividades de CIM e os sistemas associados. É assumido que o sistema CIM é a fonte de toda a informação necessária para o escalonamento. O paradigma de modelação por camadas e orientado ao objecto é utilizado em todos os componentes da arquitectura para modelação da informação e representação do conhecimento, e inclui alguns resultados conseguidos em modelação de dados em vários projectos internacionais. Foi seguida a metodologia CIM-OSA para modelar os processos dinâmicos da empresa.
Virtualização da Estrutura de Produção da Empresa - A virtualização da estrutura dos recursos de produção pretende a distribuição balanceada entre os processos de negócio e um uso mais racional dos recursos de produção, tendo em atenção toda a empresa e não apenas uma área particular - uma situação de sobrecarga ou disponibilidade total de alguns recursos de produção/áreas de produção durante o escalonamento deve ser evitado. Toda a estrutura de produção deve adaptar-se de forma flexível para poder atender mais processos de negócio novos e reagir em presença de perturbações no processo de produção. Os níveis de virtualização correspondem a uma modelação multi-nível da estrutura de produção.
Controlo Multi-Agente Distribuído - a utilização do paradigma dos sistemas multi-agente no projecto HOLOS permite que o escalonamento seja decidido por um conjunto distribuído de agentes cooperativos. Como o ambiente fabril é dinâmico, repleto de restrições e, muitas vezes, imprevisível, as restrições propagam restrições e, normalmente, é necessário negociar alguma relaxação de requisitos. É utilizado o paradigma de negociação da rede contratual ("Contract Net") [DAV83] para suportar a necessária flexibilidade na resolução de conflitos durante a geração do escalonamento e a execução. A negociação entre agentes termina com a selecção de um agente de produção (trabalhador, máquina, transporte ou robot) para executar determinada tarefa.
O sistema de escalonamento modela os recursos em duas camadas: a física e a lógica. Na camada física os recursos de produção são estáticos de acordo com a planta de fabrico instalada. Na camada virtual estes recursos de produção são vistos como um agrupamento lógico dos mesmos, sendo divididos em 2 níveis: o virtual estático e o virtual dinâmico. O nível virtual estático representa uma primeira estruturação virtual da camada física, cuja topologia é organizada em termos de funcionalidades dos recursos de produção. O nível virtual dinâmico representa uma estrutura virtual a partir da estrutura virtual estática, através da formação de um consórcio. Um consórcio representa um escalonamento descentralizado e é um agrupamento lógico, dinâmico e temporário de recursos de produção para a execução de uma tarefa.
Para suportar o sistema multi-agente citado, existem 4 tipos de agentes:
- agente de actividade empresarial ("enterprise activity agent") para o nível físico;
- agente de centro de expansão local ("local spreading center") para o nível virtual estático;
- agente de consórcio ("consortium agent") para o nível virtual dinâmico, e
- agente supervisor de escalonamento ("scheduling supervisor agent") responsável pelo controlo e pela gestão global do escalonamento, desempenhando um papel de controlador.
2.2.5 ARTOR (Artificial Organizations)
O sistema ARTOR (ARTificial ORganizations) [SHM99], tese de doutoramento de Marcos Shmeil na Faculdade de Engenharia da Universidade do Porto, aponta soluções para a modelação de empresas, através dos agentes envolventes, e implementa um tipo de negociação para a selecção de colaboradores que pode ser tida como exemplo para a formação de empresas virtuais.
O sistema ARTOR permite modelar uma sociedade de organizações baseado em metodologias de Inteligência Artificial Distribuída, especificamente Sistemas Multi-Agente. O objectivo do sistema ARTOR é guiar a implementação computacional do modelo das organizações, permitindo uma automatização de relações inter e intra organizações.
Neste sistema existem três componentes (Figura 3):
- as organizações
- um quiosque, local público de afixação de notícias
- uma interface com o utilizador.
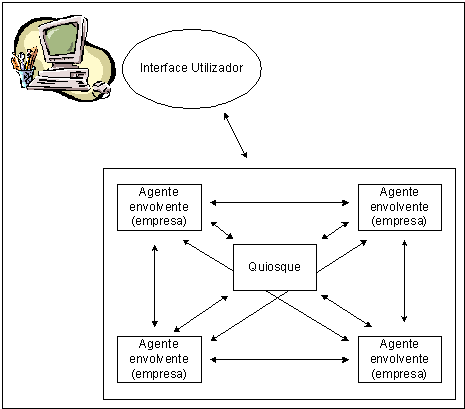
As organizações são modeladas por agentes denominados agentes envolventes. Nestes agentes as competências para exercer as actividades requeridas pelos subdomínios que constituem uma organização, são distribuídos em dois tipos de agentes:
- agentes gestores, dotados de competência para gerir a organização;
- agentes executores, dotados de competência para executar as especialidades requeridas pela organização.
Esta distribuição de competências permite explorar a execução das capacidades dos agentes de forma modular, estruturada, paralela e com diferentes graus de autonomia. Concentra a execução da especialidade nos agentes executores, modelando-os sem capacidade de planeamento e de coordenação de suas competências perante a organização. Os agentes gestores dedicam-se à satisfação dos objectivos organizacionais, gerindo de forma integrada as competências das especialidades a eles vinculadas, num certo período.
O conhecimento que pertence à organização, mas não é específico de nenhum agente, é a chamada base de conhecimento corporativa e pertence, também, ao agente envolvente. Este conhecimento é adquirido, aprendido e mantido pelos agentes internos ao agente envolvente, em função das suas relações sociais, e é orientador do comportamento dos agentes gestores e executores no desempenho das suas competências, de modo a que as actividades desempenhadas estejam de acordo com os objectivos, intenções e perfil da organização.
O quiosque, local público de afixação de notícias, disponibiliza conhecimentos sobre factos ou eventos sociais para os agentes envolventes interessados em oportunidades de negócio. Tem uma implementação baseada em metodologias de “quadro negro”, possibilitando a afixação de notícias, a gestão dos seus vínculos e a disponibilização das mesmas, quando solicitadas.
A interface com o utilizador permite visualizar as trocas de mensagens entre os componentes intra e inter-agentes envolventes. Permite, também, inquirir os agentes envolventes quanto às suas actividades e sobre o seu conhecimento.
Para assegurarem o fornecimento de um bem ou serviço, as organizações necessitam de decidir sobre os critérios que permitam avaliar o perfil de um potencial fornecedor. O processo de selecção e contratação de colaboradores, no projecto ARTOR, é baseado numa lista de critérios que expressa as dimensões que serão avaliadas nos potenciais fornecedores. Devido à diversidade de comportamentos e interesses, os potenciais fornecedores podem não concordar com os valores dos critérios, gerando uma situação de conflito que será necessariamente resolvida após uma negociação. A negociação apresenta-se, assim, como um processo de tomada de decisões.
Quando uma organização pretende o fornecimento de um bem ou serviço faz um convite à sociedade – o convite contém o serviço pretendido, até quando o convite se manterá público e uma lista de critérios com os valores pretendidos para cada critério. Este convite é afixado no quiosque, onde os agentes envolventes dos potenciais fornecedores o poderão consultar. Se houver respostas ao convite feito, o organizador passará a estabelecer uma comunicação ponto a ponto com cada potencial fornecedor.
Cada mensagem de resposta ao convite será avaliada comparando a lista de critérios afixada no quiosque (oferta) e a lista de critérios recebida da organização respondente (contra-oferta).
As diferenças encontradas na avaliação, comparando os valores iniciais da oferta e contra-oferta, obrigam a entrar numa sessão de negociação – sucessivas gerações de ofertas e contra-ofertas – que será encerrada quando:
- há igualdade de valores em todos os critérios oferecidos e contrapropostos, ou
- o número de ofertas e contrapropostas previsto pelo organizador foi atingido.
A geração das ofertas e contra-ofertas depende do estilo do agente (“win/win” ou “win/lose”) das estratégias e tácticas escolhidas pelo organizador e pelos potenciais fornecedores.
A contratação de um fornecedor, por parte do organizador, segue a prioridade:
- o fornecedor que apresentou uma contra-oferta com a melhor utilidade, independentemente de ser a última interacção, ou
- o fornecedor que antecipou o encerramento da sessão, por igualdade de valores ou, em caso de igualdade,
- o fornecedor cujo conhecimento que o organizador possui, na sua base de conhecimento sobre processos de selecção anteriores, aponta como um fornecedor “win/win”.
Os valores oferecidos e contrapropostos, durante uma sessão de negociação, geram um conjunto de exemplos que representam o comportamento de um fenómeno. A análise dos valores recebidos é feita verificando, para cada critério, se o novo valor aumenta, diminui ou mantém a utilidade global para o agente.
Estes exemplos são utilizados no processo de aprendizagem simbólica (através de raciocínio indutivo e dedutivo) contribuindo para que novos conhecimentos, sobre o comportamento dos componentes durante o processo de selecção, possam ser aprendidos.
2.3 Arquitecturas de Informação de Empresas
O projecto EIA (Enterprise Information Architectures) [BAR94], também do laboratório EIL de Toronto, pesquisa estratégias para a aquisição e distribuição de informação, de e para agentes, num ambiente distribuído, e a gestão de inconsistências (resolução de conflitos) entre a base de conhecimento local do agente e a base de conhecimento da empresa num sistema de informação multi-agente distribuído.
O projecto EIA introduz agentes mediadores chamados Agentes de Informação – IA (Information Agents) [BAR94], num ambiente distribuído de agentes. Um IA presta serviço a um grupo de agentes (funcionais e outros IAs) fornecendo-lhes uma camada de informação partilhada e serviços para a sua gestão. Os agentes funcionais registam as suas capacidades e interesses num IA. O IA recebe informação dos agentes funcionais, verifica a sua relevância para outros agentes e distribui a referida informação para aqueles agentes que a consideram importante e, se necessário, numa forma mais fácil de entender. Se a informação distribuída vier a tornar-se inconsistente, o agente de informação alertará todos os receptores. Se os agentes funcionais fornecerem informação contraditória, o IA aplicará estratégias para resolver o conflito e reinstalar a consistência.
Os agentes de informação assumem uma quantidade substancial do trabalho requerido para executar a comunicação com outros agentes, para procurar, converter e melhorar a informação e para coordenar o processo de distribuição dessa informação. Estes agentes apresentam os seguintes componentes (Figura 4):
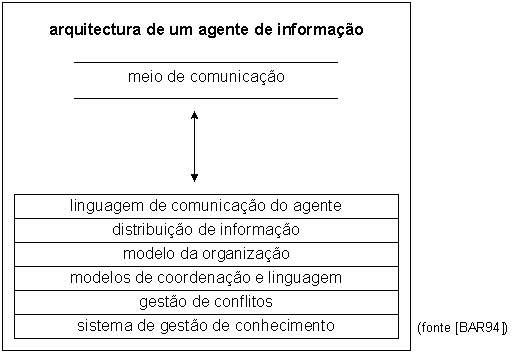
Figura
4 - Agente
de Informação (Barbuceanu e Fox)
· linguagem de comunicação do agente - a comunicação entre os agentes é feita utilizando a linguagem KQML (Knowledge Query and Manipulation Language) [FIN97] e KIF (Knowledge Interchange Format) [KIF98];
· distribuição de informação - é o serviço que distribui, de forma voluntária ou a pedido, informações de interesse para os outros agentes;
· modelo da organização - é o modelo, contido em cada agente, que descreve os papéis que os demais agentes desempenham na organização, os seus objectivos e capacidades;
· modelos de coordenação e linguagem - contêm regras declaradas numa linguagem para coordenação das acções cooperativas;
· gestão de conflitos - capacita o agente para tomar decisões quando recebe informação contraditória de outros agentes;
· sistema de gestão de conhecimento - armazena e processa o conhecimento localmente.
2.4 Infra-estruturas para Empresas Virtuais
Aproveitando a realização da conferência “PRO-VE’99 – IFIP/PRODNET Working Conference on Infrastructures for Virtual Enterprises”, Camarinha-Matos e Afsarmanesh [CAM99A] fazem o ponto da situação sobre o estado actual do desenvolvimento na área de investigação das empresas virtuais.
2.4.1 Definição de Empresa Virtual
Para Camarinha-Matos e Afsarmanesh “uma EV é uma aliança temporária de empresas que se encontram com o objectivo de partilhar recursos e competências técnicas elementares para melhor responder às oportunidades de negócio que surgem e cuja cooperação é suportada por redes de computadores”.
Esta definição descreve uma empresa virtual como uma rede de empresas colaborantes, onde cada uma é um nó de uma rede onde cabem fornecedores, consumidores e outros serviços especializados. Nenhum dos parceiros produz um produto completo mas são realizados acordos entre as várias empresas de modo a seleccionar as competências fundamentais de cada uma e surgir aos olhos do mundo como uma unidade de negócio que produz um produto ou fornece um serviço completo.
Embora o estabelecimento de acordos comerciais de cooperação entre empresas seja uma prática comum do mundo dos negócios, a característica fundamental deste novo conceito é o uso intensivo das novas tecnologias de informação e comunicação para proporcionar uma cooperação mais rápida. Com estas tecnologias a distância deixe de ser um factor limitativo e vai, naturalmente, aumentar a cooperação a nível internacional.
Este novo paradigma é fundamental para as pequenas e médias empresas (PMEs) poderem entrar em alianças estratégicas, quebrando as barreiras geográficas e ganhando competitividade no ambiente de mercado global.
2.4.2 Terminologia relacionada
A proliferação de formas de cooperação entre empresas originou um número razoável de organizações cuja estrutura se assemelha à definição de Empresa Virtual apresentada e à existência de termos relacionados:
Empresa Alargada – Conceito aplicado a uma empresa dominante que “alarga” os seus limites integrando alguns, ou a totalidade, dos seus fornecedores. É o conceito que mais se aproxima ao de EV embora nesta a estrutura seja mais democrática em termos de cooperação. Pode ser considerado um caso particular de EV.
Organização Virtual – A aliança entre empresas não integra apenas empresas produtivas mas também outro tipo de organizações não produtivas e, mesmo, não lucrativas. Uma organização de todas as empresas municipais (p.ex. água, saneamento, bibliotecas, conservatórias de registo predial, câmara municipal, museus, ...) com o objectivo de melhor informar e servir os cidadãos pode ser um exemplo deste tipo de organizações. A EV pode ser vista como uma particularidade deste conceito.
Rede de Organizações – É um conceito mais geral e refere-se a qualquer grupo de organizações ligadas por uma rede de informação mas sem obrigatoriedade de partilhar recursos e competências técnicas ou terem um objectivo comum. Penso que este conceito não corresponde a nenhum tipo de organização.
Gestão de uma Cadeia Produtiva – É uma forma existente de gerir e controlar os fluxos de material numa cadeia de valor, cobrindo praticamente todos os aspectos desde o fornecimento de matéria-prima até ao consumidor final, e que envolve os fabricantes dos produtos, os transportadores, os distribuidores, toda a cadeia de retalho e assente num fluxo de informação entre os vários participantes da cadeia produtiva. Tradicionalmente é uma gestão aplicada em grupos estáveis, onde os parceiros base se mantêm durante muito tempo mas, hoje em dia, já se encontram cadeias produtivas bastante dinâmicas. O objectivo desta forma de organização é conseguir uma logística eficiente no fluxo de materiais e produtos.
Directório de Empresas – Grupo ou aglomerado de empresas que tem o potencial e o desejo de cooperar e que poderão vir a ser participantes de EVs. Estas empresas registam-se num directório onde declaram as suas competências base (fundamentais). Será neste directório e baseados na sua informação que os iniciadores de uma EV poderão seleccionar os parceiros quando uma nova oportunidade de negócio aparecer.
2.4.3 Classificação de Empresa Virtual
Um número muito diversificado de organizações colaborantes encaixam na definição geral de EV. Para modelar completamente uma empresa no paradigma das EVs é necessário classificar a EV partindo das suas características e dos seus requisitos.
Camarinha-Matos e Afsarmanesh [CAM99A]identificam um conjunto de características de uma EV que pode ser utilizado para distinguir diferentes ambientes de EVs – duração, topologia, participação, coordenação e visibilidade.
Duração – Algumas alianças de empresas são estabelecidas para aproveitar uma oportunidade de negócio e são dissolvidas no fim desse negócio. É, talvez, a situação mais típica de uma EV, e pode ser encontrada nos consórcios de construção civil para grandes empreitadas (pontes, viadutos, auto-estradas, p.ex.). Contudo na indústria alimentar e automóvel é mais fácil encontrar alianças com um carácter mais duradouro. No primeiro caso é necessária uma infra-estrutura que suporte muito facilmente a criação / operação / dissolução de um consórcio; no segundo caso é mais importante definir muito bem as regras do negócio e a sua supervisão.
Topologia – Embora em muitos sectores as alianças estabelecidas permaneçam quase como uma estrutura fixa durante todo o processo de negócio, cada vez é mais frequente encontrar topologias dinâmicas, onde algumas empresas passam a integrar ou deixam a EV consoante a fase do processo de negócio ou factores de mercado. Neste último caso devem existir procedimentos e funcionalidades específicas para procurar e seleccionar os parceiros, manter directórios actualizados com as empresas possíveis parceiros e tratar convenientemente os processos de integração / cessação dos parceiros.
Participação – Um aspecto importante da participação numa EV é a possibilidade de uma empresa participar em várias alianças simultaneamente ou ter uma participação exclusiva numa aliança. No caso da participação não exclusiva em alianças, a infra-estrutura da empresa deve preservar convenientemente as regras de cooperação e visibilidade para manipular convenientemente os vários espaços de participação.
Coordenação – A coordenação entre os membros da EV pode ser baseada numa estrutura tipo estrela, onde uma empresa dominante impõe as regras e os restantes parceiros limitam-se a cumprir os requisitos, numa aliança democrática, onde não existe empresa dominante, ou numa federação, quando os parceiros de uma aliança bem sucedida decidem avançar para formas comuns de gestão de recursos e competências. A coordenação tipo estrela pode ser facilmente encontrada na indústria automóvel onde a empresa dominante define as “regras do jogo” e impõe os seus standards e modelos de negócio aos restantes parceiros – característica típica das empresas alargadas. Na coordenação democrática todos os parceiros colaboram de forma igual, preservando a sua autonomia mas unindo as suas competências fundamentais – nestas alianças surge, muitas vezes, um parceiro com o papel de coordenador.
Visibilidade - Até onde pode um parceiro ver a configuração da EV está dependente da topologia e da coordenação adoptadas. A visibilidade a um nível permite a cada empresa observar / conhecer apenas os seus parceiros vizinhos (fornecedores e clientes). A visibilidade a vários níveis permite a uma empresa obter informações de parceiros não vizinhos (não directamente relacionados consigo) favorecendo uma operação mais optimizada da EV e conduzindo a situações de coordenação mais avançadas. Como a tendência geral de cada empresa é esconder, tanto quanto possível, as suas informações estratégicas, só se consegue atingir a visibilidade múltipla quando a confiança entre os parceiros ultrapassa as suas desconfianças – neste caso consegue-se uma coordenação bastante melhorada da actividade da EV.
2.4.4 Etapas do ciclo de vida
Para Camarinha-Matos e Afsarmanesh [CAM99A] o ciclo de vida de uma EV pode ser decomposto em quatro fases (Figura 5):
Criação – Fase inicial da EV que engloba a sua criação e configuração. As funcionalidades requeridas são: procura e selecção de parceiros, negociação e acordo quanto à forma de participação, definição definitiva dos contratos de participação, procedimentos de aliança e dissolução, configuração, etc.
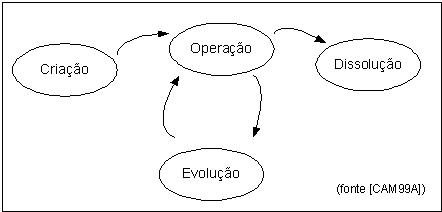
Figura 5 – Ciclo de vida de uma EV (Camarinha-Matos e Afsarmanesh)
Operação – Fase em que a EV executa o seu processo de negócio para atingir os seus objectivos. As funcionalidades desta fase são: mecanismos seguros para troca de informação, processamento de excepções e eventos, gestão de encomendas, processamento de encomendas incompletas, gestão de tarefas distribuídas, coordenação genérica, etc.
Evolução – Fase que pode existir durante a operação da EV obrigando a adicionar ou substituir um parceiro devido à sua incapacidade temporária ou definitiva, ao aumento da carga de trabalho ou qualquer outro evento excepcional. As funcionalidades desta fase coincidem com a fase de criação.
Dissolução – Fase em que a EV conclui o seu processo de negócio e termina a sua existência porque atingiu os seus objectivos ou porque os parceiros decidem acabar a operação da EV. A definição das responsabilidades e compromissos financeiros de cada parceiro envolvido é um aspecto importante a ser negociado.
2.4.5 Participantes da Empresa Virtual
Para Camarinha-Matos e Afsarmanesh [CAM99A] uma empresa pode desempenhar diferentes papéis durante o ciclo de vida de uma EV – coordenador da EV, membro da EV, fornecedor de informações ou serviços, etc.
Coordenador da EV – É o componente regulador das actividades da EV. Pode ser um nó especializado em coordenação e adicionado à EV ou o seu papel ser desempenhado por um dos membros da EV. É responsável, entre outras, pelas seguintes tarefas:
- Regista novas empresas na rede;
- Auxilia uma nova empresa a configurar-se de acordo com a infra-estrutura e regras da EV;
- Mantém um directório de informação da EV;
- Reconfigura a EV e distribui novidades acerca da evolução da rede, se necessário;
- Pode funcionar como testemunha das empresas que necessitem de um suporte de terceira parte na sua negociação com outras empresas;
- Supervisiona e coordena as várias actividades que concorrem para o seu objectivo da EV;
- Supervisiona o processo de dissolução da EV.
Membro da EV – São os componentes com diferentes capacidades que participam na EV e constituem os seus nós. As suas principais funções são:
- Recebe o primeiro contacto do consumidor;
- Estabelece contacto e interacções seguras com os outros nós;
- Executa a sua parte nas actividades da EV de acordo com o estabelecido e definido nos contratos de adesão;
- Controla o seu nível de visibilidade de informação para proteger os seus interesses e os da EV;
- Partilha e troca a informação e os produtos necessários para a cooperação com os outros membros da EV.
Directório da rede – Um ou mais nós da rede de empresas devem funcionar como directórios. Numa rede tão vasta quanto a Internet, onde muitas empresas têm acesso, podem coexistir várias EVs a operar e um nó pode pertencer a várias EVs simultaneamente. Tipicamente um nó directório é apenas de leitura e pode cobrar os seus serviços a quem recebe a sua informação.
Intermediário (broker) – Papel desempenhado por uma empresa (não necessariamente o coordenador da EV) que inicia / cria a EV facilitando a procura de parceiros.
Katzy e Obozinsky [KATZ99] propõem uma lista de participantes na EV e respectivas funções mais centradas na criação e projecto da EV:
- Intermediário – responsável por anunciar as competências da rede;
- Gestor de competências – junta as competências dos parceiros e apresenta-as aos consumidores;
- Gestor de projecto – trata das encomendas e da engenharia, controlando as restrições temporais e de orçamento e substituindo um parceiro que não tenha um desempenho satisfatório;
- Auditor – responsável pelo controlo financeiro e assessoria;
- Assistente de rede – responsável pela construção e manutenção da infra-estrutura, aquisição de parceiros e regras para as encomendas;
- Gestor de cada parceiro – responsável pela coordenação e comunicação com o gestor de projecto, disponibilizando o know-how, os recursos e a tecnologia da empresa para o mundo exterior.
2.5 PRODNET
O projecto Esprit PRODNET II – Production Planning and Management in a Virtual Enterprise, pretende desenvolver uma plataforma aberta para integrar empresas virtuais industriais pondo especial ênfase nas necessidades das pequenas e médias empresas (PMEs) industriais. Esta plataforma inclui:
- troca de mensagens comerciais através do EDIFACT (Electronic Data Interchange for Administration, Commerce and Transport) [EDI98];
- troca de dados técnicos de produto através do STEP (Standard for the Exchange of Product Model Data);
- sistema de gestão de informação distribuída / federada para suportar não apenas a informação administrativa da EV mas, também, toda a informação que os participantes da EV decidam tornar acessível ao exterior;
- módulo de coordenação que trata de todos os eventos relacionados com a cooperação (execução de planos locais de actividade);
- configurador, que permite a definição e parametrização da EV e do comportamento de cada parceiro;
- comunicações seguras;
- monitorização do estado das encomendas;
- troca de informação de qualidade entre os parceiros;
- sistema PPC (Planos de Produção e Controlo) expandido que percebe o ambiente da EV e ajuda a resolver problemas de encomendas incompletas;
- gestão distribuída do processo de negócio com coordenação, monitorização e ajuda à decisão ao nível da EV;
- procura e selecção electrónica de parceiros baseada na existência de directórios de fornecedores públicos e privados.
Este projecto é baseado no sector metalo-mecânico mas as características de flexibilidade e configuração permitem adaptar a sua infra-estrutura a outros sectores da indústria. Grande parte dos componentes do projecto PRODNET II foram facilmente adaptados ao projecto da indústria agro-alimentar INDO-DC SCM+[1] [CAM97].
2.6 NIIIP
Neste projecto norte-americano [NIIIP94] uma EV é definida como uma aliança temporária de empresas que partilha custos e competências técnicas para aproveitar mais facilmente as oportunidades de negócio que surjam no mercado. A intenção é suportar a formação de EVs industriais e fornecer tecnologia para permitir aos seus participantes colaborar num ambiente computacional heterogéneo.
Este projecto teve início em 1994 nos Estados Unidos da América e é o acrónimo de National Industrial Information Infrastructure Protocols (NIIIP). Pode considerar-se o maior projecto existente na área das EVs pois abrange o ciclo de vida completo de uma EV: identificação das necessidades do mercado, escolha de possíveis parceiros e suporte para o processo de negociação entre parceiros, instanciação, operação e dissolução da EV.
Este projecto assenta o seu desenvolvimento em tecnologias recentes:
- a Internet, suas comunicações e serviços
- OMG (Object Management Group) [OMG89] e as suas metodologias de orientação aos objectos
- STEP e suas orientações para a modelação dos dados partilhados
- Workflow Management Coalition
Reference Architecture, ...
O NIIIP propõe uma arquitectura de referência com base nestas tecnologias que integra e amplia os protocolos existentes. Alguns projectos piloto avançaram com base na arquitectura proposta mas ainda se encontram na fase de protótipos – o SMART (Solutions for Small and Medium Enterprises Adaptable Replicable Technology) [BARR98] é um exemplo.
Embora o projecto NIIIP proponha uma arquitectura base que deve ser considerada em qualquer projecto de desenvolvimento de EVs, a sua ligação à realidade e interesses do mercado norte-americano pode dificultar a sua transposição para outros mercados. Com efeito a sua visão do mundo empresarial é demasiado harmoniosa, todas as empresas se apresentam com uma atitude colaborativa e partilhando todo o tipo de recursos, incluindo os humanos, o que é demasiado optimista para as realidades europeia ou asiática, por exemplo.
2.7 Conclusões
Apesar dos esforços de desenvolvimento e do progresso atingido nas áreas de infra-estruturas, mecanismos e ferramentas para suportar empresas virtuais, existem ainda muitos campos abertos para investigação e cooperação. Ainda não existem soluções definitivas ou, pelo menos, unanimemente aceites sobre, por exemplo:
- standards para troca de informações;
- comunicações seguras e independência dos canais;
- suporte para todo o ciclo de vida de uma EV;
- interacção entre aplicações de empresas;
- gestão dos contratos celebrados;
- ferramentas de configuração;
- procura e selecção dos parceiros.
Como muitos dos esforços de desenvolvimento na área das empresas virtuais têm sido concentrados no projecto e desenvolvimento de infra-estruturas e suporte para a fase de operação das empresas industriais, este trabalho pretende dar um contributo para a fase de formação das empresas virtuais.
3 Projecto de um Sistema Multi-Agente para a Formação de uma Empresa Virtual
O desafio lançado para este projecto foi a apresentação de uma plataforma computacional capaz de integrar uma arquitectura multi-agente para simular a constituição de uma empresa virtual (EV) cujo processo implica:
- Descrição no sistema do objectivo da EV (serviços a satisfazer ou produtos a fornecer);
- Colecção das propostas das empresas individuais (agentes) interessadas em pertencer à EV;
- Negociação entre os potenciais membros para selecção do melhor conjunto destes. Os serviços a negociar têm descrição multi-atributo e podem existir restrições mútuas entre atributos de diferentes serviços. Os serviços a negociar devem satisfazer critérios de utilidade múltipla, por exemplo, preço, prazos de entrega, qualidade, etc.
O objectivo principal é estudar métodos que permitam incluir restrições em negociação entre agentes distribuídos na formação de empresas virtuais. Os serviços negociados não sendo independentes propagam restrições entre eles.
São abordadas duas formas de considerar o problema da
negociação baseadas na descrição do produto ou serviço:
- descrição quantitativa, onde se atribuem valores de utilidade diferentes aos atributos que compõem um determinado produto, para distinguir a importância relativa de cada um deles;
- descrição qualitativa, onde em vez de valores se impõe uma ordem de preferência aos atributos.
A propagação das restrições e a consequente negociação para resolução de conflitos deve poder utilizar as duas descrições.
3.1 Descrição do trabalho
O projecto realizado tenta responder a uma série de questões que se levantaram, do ponto de vista da implementação, no seu início, nomeadamente:
- que linguagem de programação utilizar?
- que arquitectura adoptar para o sistema multi-agente (SMA)?
- que tipos de agentes? Qual a sua arquitectura? Quantos? Para quê?
- que tipo de comunicação existirá entre os agentes?
- qual a linguagem para a troca de informação entre os agentes?
- cada agente será, computacionalmente, um processo ou um thread?
A preocupação de desenvolver uma plataforma computacional flexível que possa ir evoluindo à medida que novos componentes são construídos levou às seguintes decisões:
- utilizar a linguagem de programação Java (secção 4.1) – é muito fácil acrescentar novos componentes;
- utilizar o Jini (secção 4.2) como infra-estrutura para a construção do sistema distribuído – a ligação de novos componentes é feita na base ‘plug-and-work’;
- utilizar o serviço JavaSpaces (secção 4.3) do Jini como infra-estrutura de comunicações entre os agentes.
Esta plataforma, por ser completamente construída em Java (Jini e JavaSpaces são conjuntos de classes Java), é perfeitamente portável para qualquer ambiente de computação, seja Unix, Linux, Windows ou Macintosh - basta ter uma Java Virtual Machine (JVM).
A arquitectura de agentes adoptada por este trabalho é inspirada nas arquitecturas propostas para comércio electrónico, por Rocha [ROC98] e Cardoso [CAR00], e formação de empresas virtuais, por Rocha [ROC99], Shmeil [SHM99] e Oliveira [OLI00], desenvolvidas, ou em desenvolvimento, no Núcleo de Inteligência Artificial Distribuída e Robótica (NIAD&R), do Laboratório de Inteligência Artificial e Ciência de Computadores (LIACC) da Universidade do Porto. Estas arquitecturas envolvem, basicamente, três tipos de agentes:
- agentes que representam empresas,
- um agente mercado electrónico onde as empresas se dão a conhecer e onde são afixadas as oportunidades de negócio,
- agentes de interface aos utilizadores para configuração e interacção com o mercado.
Serão desenvolvidos dois tipos de agentes: o agente empresa que representará uma empresa, ou parte dela, a quem foi conferida autonomia e conhecimento para poder negociar e tomar decisões em nome da empresa, e o agente interface utilizador que permitirá configurar os agentes empresa e dialogar com eles para extrair informação, por exemplo, registo histórico de anteriores negociações e saber que agentes estão activos no mercado.
O agente mercado electrónico é substituído por um espaço de comunicação e interacção implementado pelo serviço JavaSpaces. Neste espaço, ou mercado, as empresas registam os seus interesses e são notificadas sempre que uma oportunidade de negócio, que inclua um dos seus interesses, for lançada no mercado.
A comunicação entre os agentes far-se-á, assim, através do mercado onde qualquer mensagem terá sempre a identificação da origem e do destino, sendo este suprimido sempre que a mensagem não tenha um destinatário único. As mensagens são classes Java devidamente instanciadas (objectos) que entram e saem do mercado à medida que são escritas ou lidas. A notificação é realizada à custa dos eventos remotos Jini suportados pela API do JavaSpaces.
Com esta estrutura é muito fácil para as empresas entrar e sair do mercado em qualquer altura, sendo indiferente a localização de cada empresa – desde que saiba identificar o mercado, pelo seu nome, automaticamente pode fazer parte dos possíveis elementos de uma futura empresa virtual.
O protocolo de negociação adoptado tem como objectivo validar, de certa forma, o modelo de negociação apresentado em alguns dos trabalhos de Oliveira e Rocha citados anteriormente ([OLI99] [OLI00] [ROC99] [ROC00]). Nestes trabalhos são formalizadas as descrições quantitativas [ROC99] e qualitativas [ROC00], o protocolo de negociação da comunidade multi-agente, o anúncio do serviço, a formulação da proposta, as contra-ofertas, a evolução das propostas, a negociação de restrições e o fecho da negociação. Alguns pormenores foram acrescentados durante a execução do protótipo.
O sistema - VESM (Virtual Enterprises Space Market) - tem na sua origem o nome do mercado JavaSpaces – VESpaceMarket.
Neste sistema todos os agentes são, do ponto de vista computacional, threads.
3.2 Estrutura do Sistema Multi-Agente
Um agente é uma entidade computacional que dispõe de capacidade para perceber o seu ambiente exterior, é capaz de intervir nesse mesmo ambiente de forma flexível e com algum grau de autonomia, guiado por objectivos próprios e com eventual capacidade para aprender com a experiência de modo a melhorar o seu desempenho [JEN96].
Um sistema multi-agente pode ser definido como uma rede fracamente ligada de agentes que trabalham em conjunto para resolver problemas que ultrapassam a capacidade e conhecimento de cada um em particular.
Os sistemas multi-agente, sistemas projectados e implementados com vários agentes interactivos, são especialmente adaptados para representar problemas com múltiplas possibilidades de solução, múltiplas perspectivas e múltiplas entidades. Estes sistemas possuem capacidade para resolver problemas tradicionalmente distribuídos e possibilitam sofisticados padrões de interacção: cooperação (trabalhar em conjunto para um objectivo comum), coordenação (organizando a resolução de problemas através da exploração de interacções benéficas e evitando interacções prejudiciais) e negociação (tentando atingir um acordo que seja aceitável para todas as partes envolvidas). A flexibilidade e o alto nível das interacções são a base deste potente paradigma e distinguem os sistemas multi-agente de outras abordagens [JEN98].
A arquitectura de agentes adoptada por este trabalho (Figura 6) é inspirada nas arquitecturas propostas para comércio electrónico e formação de empresas virtuais referidas anteriormente ([ROC98] [CAR00] [ROC99] [SHM99] [OLI00]).
Cada empresa, ou parte de empresa, será representada por um agente a quem foi conferida autonomia e autoridade para tomar decisões em nome da sua representada (empresa). Para tal o agente é dotado de conhecimento sobre a própria empresa (modelo), a sua capacidade, os seus interesses, as suas responsabilidades e direitos, bem como de conhecimento sobre os outros agentes. Possui também capacidade de comunicação com o mundo exterior (outros agentes) e capacidade de planear e coordenar as suas actividades, de forma a poder formular respostas a convites recebidos para pertencer à EV. No modelo de empresa que o agente possui estão incluídas as tácticas e as estratégias de negociação que venha a adoptar, quando tentar pertencer a uma EV.
A interface com o utilizador poderá ser realizada com um ou mais agentes, dependendo da complexidade pretendida.
Um utilizador normal poderá dialogar com os agentes de empresa para recolher, por exemplo, dados sobre os seus interesses, os serviços que pode fornecer, os serviços que requisitou, as empresas virtuais a que já pertenceu (histórico) ou pertence e saber que serviços estão a ser negociados, com que empresas está a negociar.
Um utilizador devidamente autorizado poderá introduzir dados para criar ou alterar a caracterização de uma empresa e acompanhar as fases de negociação em que a empresa estiver envolvida. É este utilizador que introduz os dados iniciais de conhecimento no agente empresa: o modelo da empresa e as características dos serviços que pode fornecer ou quer requisitar. Também pode introduzir conhecimento prévio sobre outras empresas. Durante a negociação pode observar as mensagens que o seu agente troca com outros agentes e acompanhar o processo de aprendizagem do agente. Pode também saber que restrições foram negociadas, em que circunstâncias, com quem e o seu custo, além de poder fiscalizar o desempenho da empresa dentro da EV.
A interacção entre utilizadores e agentes utiliza a mesma infra-estrutura de comunicação que os agentes utilizam para comunicar entre si. Contudo o agente de interface deve conter mecanismos que traduzam os padrões de conversação entre agentes em padrões que o utilizador possa ver e entender. Os utilizadores devem ficar isolados dos aspectos formais da linguagem utilizada pelos agentes.
O agente mercado electrónico, normalmente responsável por coordenar os pedidos de formação das Empresas Virtuais, onde são afixados os serviços a satisfazer por uma EV e que também funciona como uma infra-estrutura de comunicações e informação, pois é o local que todas as empresas conhecem e onde poderão encontrar as restantes empresas, foi substituído pelo espaço VESpaceMarket, uma implementação do serviço JavaSpaces da plataforma Jini. Este serviço não funciona como coordenador da formação da EV mas proporciona todas as outras funcionalidades apresentadas. Senão vejamos:
Tradicionalmente cada empresa afixa, no mercado electrónico, os serviços que pode fornecer. Fica assim registada como empresa potencialmente interessada em fazer parte de uma EV.
Se uma empresa necessitar que lhe forneçam serviços, afixa no mercado os serviços que pretende ver satisfeitos. Fica assim registada como sendo a entidade consumidora à qual a EV vai prestar serviço e, como tal, é a entidade que coordenará a negociação com as demais empresas e determinará quem pertence à EV.
A cada empresa fornecedora de serviços, registada no mercado, é feito um convite inicial para pertencer à EV com a proposta de fornecimento de serviço.
A negociação que se segue para a formação da EV pode, ou não, ter a interferência deste agente que deve, contudo, ser informado da conclusão das negociações e retirar o pedido de fornecimento dos serviços negociados.
As vantagens deste agente são:
- menor comunicação inicial no anúncio do fornecimento do serviço - a empresa que o pretende apenas o anuncia uma vez e só as empresas que têm capacidade para fornecer esse serviço serão contactadas;
- maior facilidade em se relacionarem empresas que inicialmente não se conhecem - a empresa que anuncia o serviço requerido pode conhecer, apenas, o local público de afixação de notícias, sem ter conhecimento das empresas fornecedoras;
- local que contém toda a informação sobre as empresas virtuais formadas e os serviços fornecidos;
- especialização deste agente em determinado tipo de serviços.
A desvantagem mais relevante é este agente ser um ponto susceptível de provocar estrangulamento nas comunicações.
No sistema VESM (Figura 6) o processo conducente à formação da EV é o seguinte:
Como o espaço VESpaceMarket tem características de persistência e acesso distribuído é o ideal para comunicações robustas e fiáveis. As suas facilidades de notificação e distribuição de eventos remotos permite que os agentes empresa registem os seus interesses “pedindo” que o espaço os notifique sempre que uma oportunidade de negócio inclua um dos seus interesses.
O registo inicial das empresas e os seus interesses e o anúncio público para fornecimento de um serviço mantêm-se como no processo tradicional: o registo dos interesses das empresas é realizado através da facilidade de notificação ao VESpaceMarket; se uma empresa pretende o fornecimento de um serviço anuncia-o no mercado devidamente caracterizado, ou seja, dividido nos sub-serviços ou subprodutos que o compõem – este anúncio é acompanhado da identificação da empresa que o lançou.
O convite que era feito pelo agente mercado às empresas fornecedoras é, agora, automaticamente feito pelo VESpaceMarket sem necessidade de código adicional – faz parte das próprias facilidades do JavaSpaces notificar através de eventos remotos.
A negociação entre as empresas utiliza o VESpaceMarket como plataforma de comunicações.
A simplificação na implementação do código relativamente ao processo tradicional é uma enorme vantagem pois apenas ficamos reduzidos a dois tipos de agentes.
3.2.1 Arquitectura dos Agentes
A arquitectura de cada um dos agentes envolvidos não difere muito da apresentada por Rocha e Oliveira [ROC99].
A estrutura de cada agente empresa inclui três módulos funcionais: comunicações, coordenação e execução e dois módulos de conhecimento: conhecimento individual da empresa e conhecimento corporativo (ver Figura 7).
O módulo de comunicações é responsável por toda a manipulação das mensagens, ou seja, pela interligação com o espaço VESpaceMarket. A troca de mensagens com as outras empresas é sempre realizada através do mercado, que funciona como um posto de correio.
O módulo de coordenação e tomada de decisões é o responsável pela formulação das propostas (em resposta a um anúncio de oportunidade de negócio ou como resposta a uma contra-proposta). Neste módulo é também integrada a aprendizagem como forma de reformular respostas à medida que o processo da negociação decorre e à medida que fizer ou não parte de EVs.
O módulo de execução local tem pouca importância neste contexto pois não intervém na negociação – é responsável, apenas, pela execução de tarefas próprias do agente na sua relação com a empresa.
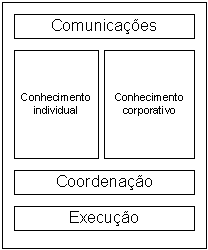
Figura 7 - Arquitectura do agente empresa
O módulo de conhecimento individual da empresa é o que contém a informação do próprio agente: capacidades próprias de produção, condições de negociação e informação que lhe tenha sido introduzida sobre outros agentes. É este o módulo que contém o modelo da empresa e onde residem as tácticas de negociação que o agente utilizará.
O módulo de conhecimento corporativo, ou do mundo exterior, contém informação sobre os direitos e deveres das empresas em geral, e sobre as empresas virtuais de que vai fazendo parte.
O agente utilizador terá apenas dois módulos: o de comunicações e o de interface gráfica (ver Figura 8).
O módulo de comunicação é responsável pela troca de mensagens com as empresas através do espaço VESpaceMarket.
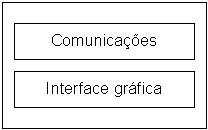
Figura 8 - Arquitectura do agente utilizador
3.2.2 Descrição Formal dos Objectivos da Empresa Virtual
Os objectivos para a formação de uma empresa virtual são introduzidos pelo utilizador durante a fase de configuração das empresas. A configuração pode ficar armazenada em ficheiro, forma mais robusta, ou ser introduzida online durante o funcionamento do sistema. O ficheiro de configuração terá o nome de cada empresa e, quando o sistema arranca, são lançados os agentes empresa. Cada agente lê o seu ficheiro de configuração ficando à espera que um utilizador lhe dê autorização para entrar no mercado. A partir deste momento pode iniciar-se um processo de formação de empresa virtual.
As capacidades de cada empresa, os subprodutos que pode fornecer, as condições de negociação, as restrições impostas a valores de atributos entre subprodutos, etc. também estão descritas nesse ficheiro inicial de configuração.
Cada produto ou serviço a fornecer (classe Product) é descrito por uma identificação, uma lista dos subprodutos que o constituem e uma lista de condições para a negociação. Na lista de condições tem obrigatoriamente que existir a condição Deadline para limitar a duração da negociação.
Product (Pid, SPL, NCL)
Pid – identificação do produto
SPL – lista de subprodutos que compõem o produto
NCL – lista de condições de negociação para o produto
Cada subproduto (classe SubProduct) é descrito por uma identificação, uma lista de atributos e uma lista de condições de negociação. Na lista de atributos tem que existir, obrigatoriamente, o atributo Price. Na lista de condições de negociação pode existir, também, a condição Deadline mas a que será considerada na negociação é a mais restritiva das duas (a indicada no produto e a do subproduto).
SubProduct (SPid, AtL, NCL)
SPid – identificação do subproduto
AtL – lista de atributos que caracterizam o
subproduto
NCL – lista de condições de negociação para o subproduto
Na descrição qualitativa de um subproduto a lista de atributos está ordenada por preferências crescentes.
Cada atributo (classe Attribute) é descrito, quantitativamente, por uma identificação, um domínio de valores possíveis, um valor preferido e uma utilidade associada que revela a importância relativa deste atributo no conjunto do subproduto. Se a descrição for qualitativa, apenas a identificação e o domínio de valores são introduzidos (classe AttributeDomain).
Attribute
(AtD, Vp, Ut)
AtD – AttributeDomain:
Atid – identificação do atributo
D – domínio de valores possíveis
Vp – valor preferido
Ut – utilidade associada ao atributo
Numa descrição quantitativa o domínio de valores possíveis (classe Domain) é descrito por um tipo (discreto-DD ou contínuo-CD), por uma conversão (linear-LR, polinomial-PL ou segmentada-PC), por um conjunto de pontos e pelos coeficientes de um polinómio (no caso dos domínios contínuos com conversão linear ou polinomial). Se o domínio for discreto o conjunto de pontos são os pares de valores possíveis (valor, classificação). Se o domínio for contínuo e tiver conversão linear ou polinomial o conjunto de pontos é constituído pelos valores extremos possíveis (mínimo e máximo). Neste caso são preenchidos os coeficientes do polinómio (da a0 a an). Se o domínio for contínuo e tiver conversão segmentada, no conjunto de pontos estão definidos os extremos de cada segmento de recta (valor, classificação).
Numa descrição qualitativa além do tipo de domínio (discreto ou contínuo) é definido o conjunto de pontos possíveis – se o domínio for discreto os valores são listados e ordenados por ordem crescente, se o domínio for contínuo apenas são apresentados os valores extremos do domínio – o menos e o mais preferido.
Domain (T, Cv, Pt, An) [descrição
quantitativa]
T – domínio discreto-DD ou contínuo-CD
Cv – conversão linear-LR, polinomial-PL ou
segmentada-PC
Pt – pontos:
DD – pontos (valor, classificação)
CD-PC – pontos extremos dos segmentos de recta
(valor, classificação)
CD-LR, CD-PL – valores extremos do domínio
An – coeficientes do polinómio (a0, a1, ..., an) – CD-LR, CD-PL
Domain (T, Pt) [descrição
qualitativa]
T – domínio discreto-DD ou contínuo-CD
Pt – pontos:
DD – pontos ordenados por ordem crescente
CD – pontos extremos do domínio – o menos e o mais preferido
As várias opções para a negociação de um subproduto, que uma empresa fornecedora tem à disposição, são definidas na classe Option descrita por uma identificação (única por fornecedor), pela identificação do subproduto e pela lista de atributos considerados para a negociação.
Option (Oid, SPid, LAp)
Oid – identificação da opção
– única por fornecedor
SPid – identificação do
subproduto
LAp – lista de atributos do
subproduto considerados na negociação
As opções que propagam restrições para outros subprodutos são definidas nos fornecedores na classe OptionConstraint. Esta classe contém a identificação da opção que impõe restrições, a identificação do subproduto e os valores dos atributos que impõem a restrição e a identificação do subproduto e os valores dos atributos restringidos.
OptionConstraint (Oid, PSR, PSC)
Oid – identificação da opção
que impõe esta restrição
PSR – identificação do
subproduto e par atributo/valores que impõem a restrição:
SPid – identificação do subproduto que restringe
AtD – AttributeDomain: atributo e domínio de valores que restringem
PSC – identificação do
subproduto e par atributo/valores que são restringidos:
SPid – identificação do subproduto restringido
AtD – AttributeDomain: atributo e domínio de valores restringidos
3.3 Estrutura de contratação no mercado (negociação)
Todas as comunicações entre os agentes do sistema são realizadas através do espaço VESpaceMarket. Neste espaço cada mensagem é uma instância de uma classe Java que implementa a interface Entry (secção 4.3.2.2). O envio de uma mensagem de um agente para outro é a passagem de um objecto (instância de uma classe) de um agente para outro através da utilização dos métodos da API do JavaSpaces (descritos na secção 4.3.2.2).
Quando um agente quer escrever uma mensagem utiliza o método write com uma instância da classe que representa a mensagem desejada.
A leitura de uma mensagem, através dos métodos read ou take, envolve um passo intermédio que é definir um padrão (template) com o tipo de mensagem que se quer ler. Este padrão é uma instância de uma determinada classe (mensagem) – se os campos do padrão não estiverem preenchidos qualquer instância da classe existente no espaço é válida; se existirem campos da classe preenchidos, é válida qualquer instância da classe que verifique, por igualdade simples, os campos preenchidos.
Quando um agente quer ser avisado de que chegou ao espaço uma determinada mensagem, instancia um padrão da mensagem (classe) pretendida com os campos preenchidos da forma que lhe interessa. Invoca depois o método notify. Quando um objecto com aquelas características chegar ao espaço o agente é notificado e pode ir ler a mensagem ao espaço.
3.3.1 Protocolo de negociação
Quando uma empresa pretende o fornecimento de um serviço ou produto, instancia a classe Product e envia para o VESpaceMarket, por cada subproduto que faz parte do produto, uma instância da classe Announcement (Figura 9). Esta classe possui a identificação da empresa consumidora e do subproduto pretendido:
Announcement
(client, subProduct)
client – identificação da empresa consumidora
subProduct – subproduto que se pretende adquirir
As empresas fornecedoras do subproduto em causa estão à espera de ser notificadas do anúncio através de um padrão da classe Announcement com o campo subProduct.SPid instanciado com o valor da identificação do subproduto. Quando o padrão for igualado, a empresa fornecedora é notificada e invoca o método read da API do JavaSpaces. A instância da classe Announcement permanecerá no espaço até expirar o prazo para a negociação (responsabilidade do VESpaceMarket) ou até estar concluída a negociação (responsabilidade da empresa consumidora).
Se for possível formular uma proposta é iniciada uma sessão de negociação com a empresa client e enviada para o VESpaceMarket uma instância da classe Proposal com as seguintes características:
Proposal
(supplier, client, Pi, SPid, LAp, LNCp)
supplier – identificação da empresa fornecedora
client – identificação da empresa consumidora
Pi – identificação da proposta (única para supplier)
SPid – identificação do subproduto que se pretende
fornecer
LAp – lista com os valores propostos para os
atributos do subproduto
LNCp – lista com as condições de negociação propostas
A empresa consumidora está à espera de ser notificada da existência de uma proposta através de um padrão da classe Proposal com o campo client instanciado com a sua identificação e o campo SPid instanciado com a identificação de um dos subprodutos que anunciou. Quando o template for igualado a proposta é retirada do VESpaceMarket invocando o método take da API do JavaSpaces.
Neste momento a empresa consumidora inicia uma sessão de negociação com a empresa fornecedora supplier para o subproduto SPid.
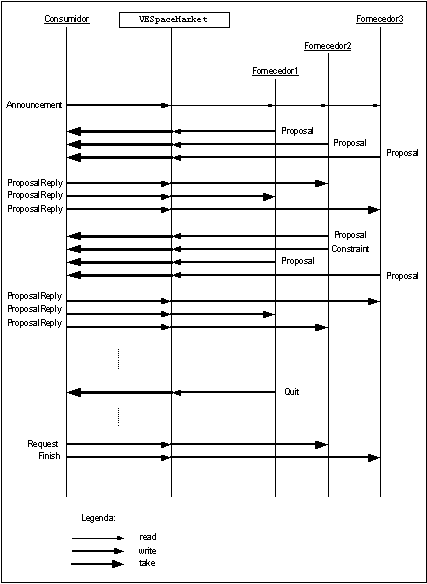
Figura 9 - Protocolo de Negociação
A proposta é analisada, juntamente com outras que entretanto tenham chegado ou venham a chegar, e é enviada para a empresa fornecedora uma mensagem de resposta à proposta Pi anterior com o resultado da avaliação da mesma (ver secção 3.3.2). É enviada para o VESpaceMarket uma instância da classe ProposalReply com as seguintes características:
ProposalReply (client, supplier, Pi, aval, reply, LAr,
LNCr)
client – identificação da empresa consumidora
supplier – identificação da empresa fornecedora
Pi – identificação da proposta à qual está associada
esta resposta
aval – avaliação global da proposta
reply – resultado comparativo da proposta Pi relativamente a propostas de outros
fabricantes para o mesmo subproduto (ganhadora ou não ganhadora)
LAr – lista com a avaliação comparativa dos
atributos face ao melhor valor proposto para cada um. Par (X,Y) onde X=Atid e Y=reason.
LNCr – lista com a resposta às condições de negociação propostas
Após enviar uma proposta, qualquer empresa fornecedora fica à espera de ser notificada da avaliação dessa mesma proposta pela empresa consumidora, através do padrão da classe ProposalReply com o campo supplier instanciado com a sua identificação. Quando o padrão for igualado a resposta à proposta é retirada do VESpaceMarket através do método take.
Após retirar a resposta à proposta Pi a empresa fornecedora irá tentar, se for possível e esta não tenha sido uma proposta ganhadora, formular nova proposta e o processo repetir-se-á até que a empresa consumidora encomende o subproduto, termine a sessão de negociação por ter encomendado o subproduto a outra empresa ou a empresa fornecedora deixe de participar na negociação por não ter condições para fazer melhores propostas.
Quando a empresa fornecedora já não consegue fazer propostas melhores para um determinado subproduto envia para o VESpaceMarket uma instância da classe Quit ao mesmo tempo que termina a sessão de negociação que estava aberta:
Quit (supplier, client, SPid)
supplier – identificação da empresa fornecedora
client – identificação da empresa consumidora
SPid – identificação do subproduto
A empresa consumidora espera ser notificada do abandono de uma
negociação por parte de uma empresa fornecedora através do padrão da classe Quit com o campo client instanciado com a sua
identificação. Quando o padrão for igualado a mensagem é retirada do VESpaceMarket através do método take e a sessão de negociação
aberta com a empresa supplier para o
subproduto SPid é encerrada.
Quando a empresa consumidora pretende encomendar um subproduto a uma empresa fornecedora envia para o VESpaceMarket uma instância da classe Request:
Request (client, supplier, Pi)
client – identificação da empresa consumidora
supplier – identificação da empresa fornecedora
Pi – identificação da proposta ganhadora
Qualquer empresa fornecedora espera ser notificada de uma
encomenda através do padrão da classe Request
com o campo supplier instanciado com
a sua identificação. Quando o padrão for igualado a encomenda é retirada do VESpaceMarket através do método take. Isto quer dizer que a
empresa faz parte da EV - é posteriormente encaminhada, a nível interno, a
encomenda para a rede produtiva da empresa e são desencadeados os mecanismos de
controlo da sua participação na EV.
Se uma empresa fornecedora recebe a encomenda de um determinado subproduto, as restantes empresas fornecedoras que se encontravam a negociar esse mesmo subproduto são avisadas do fim do processo negocial. Para isso a empresa consumidora envia para o VESpaceMarket uma instância da classe Finish:
Finish
(client, supplier, SPid)
client – identificação da empresa consumidora
supplier – identificação da empresa fornecedora
SPid – identificação do subproduto
Qualquer empresa fornecedora deve prever ser notificada do
encerramento de uma negociação através do padrão da classe Finish com o campo supplier instanciado com a sua
identificação. Quando o padrão for igualado a mensagem é retirada do VESpaceMarket através do método take. A sessão de negociação
aberta com a empresa client para o
subproduto SPid é encerrada.
Durante a fase de negociação é possível que uma empresa fornecedora, para formular uma proposta melhor, imponha restrições [OLI00] aos valores de determinados atributos de subprodutos relacionados. Estas restrições devem ser participadas à empresa consumidora pois podem influenciar a negociação de outros subprodutos. Neste caso é enviada para o VESpaceMarket uma instância da classe Constraint por cada restrição imposta:
Constraint (supplier, client, Pi, PSR, PSC)
supplier – identificação da empresa fornecedora
client – identificação da empresa consumidora
Pi – identificação da proposta à qual está associada
esta restrição
PSR – identificação do subproduto e par
atributo/valores que impõem a restrição:
SPid – identificação do
subproduto que restringe
AtD – AttributeDomain: atributo e domínio de
valores que restringem
PSC – identificação do subproduto e par
atributo/valores que são restringidos:
SPid – identificação do
subproduto restringido
AtD – AttributeDomain: atributo e domínio de valores restringidos
A empresa compradora está sempre à espera de ser notificada da existência de restrições através do padrão da classe Constraint com o campo client instanciado com a sua identificação. Quando o padrão for igualado a encomenda é retirada do VESpaceMarket através do método take e anexado à proposta Pi do fornecedor supplier.
No final da negociação, e após terem sido contratados os subprodutos aos diversos fornecedores, se a proposta Pi for a ganhadora é verificado se as restrições impostas condicionam algum dos valores de atributos entretanto contratados noutros subprodutos. Em caso afirmativo (Figura 10) são enviadas, para as empresas fornecedoras dos subprodutos restringidos, mensagens ConstraintResolution que indicam o fornecedor e a proposta que restringe e porquê:
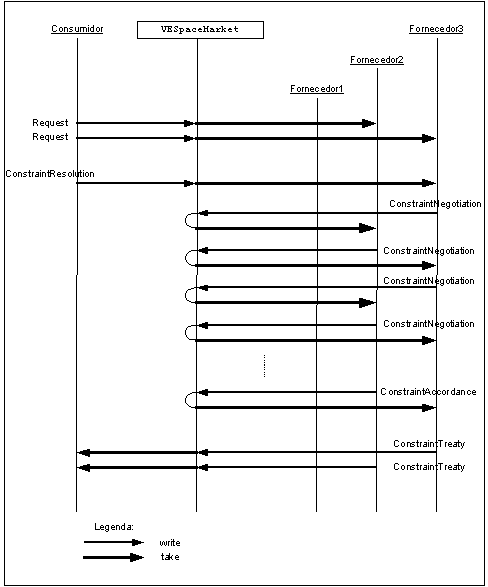
Figura 10 - Protocolo para resolução da satisfação das restrições
ConstraintResolution (client, supplier, cid, PS1, PS2)
client – identificação da empresa consumidora
supplier – identificação da empresa fornecedora
restringida (iguala cid.supplier2)
cid – identificação dos fornecedores envolvidos e
das propostas com restrições
client – identificação da empresa consumidora
supplier1– identificação da empresa fornecedora que
impõe a restrição
Pi1 – identificação da proposta do supplier1 que impõe a restrição
supplier2 – identificação da empresa fornecedora
restringida
Pi2 – identificação da proposta do supplier2 que é restringida
PS1 – identificação do subproduto e par
atributo/valores que impõem a restrição:
SPid – identificação do subproduto que restringe
AtD – AttributeDomain: atributo e domínio de
valores que restringem
PS2 – identificação do subproduto e par atributo/valores
que são restringidos:
SPid – identificação do subproduto restringido
AtD – AttributeDomain: atributo e domínio de valores restringidos
Qualquer empresa fornecedora pode ter subprodutos com atributos restringidos. Por isso, desde que tenha sido contratada para fornecer um subproduto, deve estar à espera de ser notificada do facto através do padrão da classe ConstraintResolution com o campo supplier instanciado com a sua identificação. Quando o padrão for igualado a mensagem é retirada do VESpaceMarket através do método take e iniciada uma sessão de resolução de restrições entre os fornecedores supplier1 e supplier2. supplier2 foi o fornecedor que recebeu a mensagem, o que sabe que tem atributos restringidos, e toma a iniciativa de negociar a resolução do conflito de restrições mútuas com o supplier1 enviando, para este, a mensagem ConstraintNegotiation. Esta mensagem é gerada tendo por base o método de resolução do problema de satisfação de restrições apresentado no trabalho de Rocha e Oliveira [ROC00], que tenta minimizar o decréscimo do valor de utilidade conjunta (ver 3.3.4):
ConstraintNegotiation
(supplierA, supplierB, cid, SolL)
supplierA – identificação da empresa fornecedora que
propõe esta possível solução
supplierB – identificação da empresa fornecedora que
recebe esta possível solução
cid – identificação dos fornecedores envolvidos e
das propostas com restrições
client – identificação da empresa consumidora
supplier1– identificação da empresa fornecedora que
impõe a restrição
Pi1 – identificação da proposta do supplier1 que impõe a restrição
supplier2 – identificação da empresa fornecedora
restringida
Pi2 – identificação da proposta do supplier2 que é restringida
SolL – lista de soluções possíveis. Cada solução é
composta por:
PSA – solução parcial proposta por supplierA:
SPid – identificação do subproduto de supplierA
AtD – AttributeDomain: atributo e domínio de
valores propostos
PSB – solução parcial proposta por supplierB:
SPid – identificação do subproduto de supplierB
AtD – AttributeDomain: atributo e domínio de
valores propostos
dU – decréscimo global da utilidade associado a esta solução
Qualquer empresa fornecedora pode ter que resolver conflitos com restrições e, por isso, deve estar à espera de ser notificada do facto através do padrão da classe ConstraintNegotiation com o campo supplierB instanciado com a sua identificação. Quando o padrão for igualado a mensagem é retirada do VESpaceMarket através do método take e continuada uma sessão de resolução de restrições entre os fornecedores supplierB e supplierA. supplierA foi o fornecedor que enviou a mensagem e que propõe a lista de soluções apresentada - nela está o resultado de anteriores propostas do supplierB com o valor do decréscimo de utilidade conjunta de cada solução já afectado do cálculo em supplierA.
A sessão de negociação para a resolução do problema das restrições termina quando é alcançado um valor mínimo para o decréscimo total da utilidade conjunta. A empresa que o encontrou envia para a outra empresa fornecedora a mensagem ConstraintAccordance com o seguinte conteúdo:
ConstraintAccordance
(supplierA, supplierB, cid, SolL)
supplierA – identificação da empresa fornecedora que
propõe esta solução
supplierB – identificação da empresa fornecedora que
recebe esta solução
cid – identificação dos fornecedores envolvidos e
das propostas com restrições
client – identificação da empresa consumidora
supplier1– identificação da empresa fornecedora que
impõe a restrição
Pi1 – identificação da proposta do supplier1 que impõe a restrição
supplier2 – identificação da empresa fornecedora
restringida
Pi2 – identificação da proposta do supplier2 que é restringida
SolL – lista de soluções acordadas. Cada solução é
composta por:
PSA – solução parcial proposta por supplierA:
SPid – identificação do subproduto de supplierA
AtD – AttributeDomain: atributo e domínio de
valores propostos
PSB – solução parcial proposta por supplierB:
SPid – identificação do subproduto de supplierB
AtD – AttributeDomain: atributo e domínio de
valores propostos
dU – decréscimo global da utilidade associado a esta solução
A lista de soluções é, normalmente, composta por uma só solução.
Ambos os fornecedores enviam, então, para a empresa consumidora o acordo encontrado com os valores negociados dos subprodutos restringidos. A mensagem com esta informação é a ConstraintTreaty:
ConstraintTreaty
(supplier, client, Pi, PartialSolution)
supplier – identificação da empresa fornecedora
client – identificação da empresa consumidora
Pi – identificação da proposta afectada por
restrições
PartialSolution – solução parcial proposta por supplier:
SPid – identificação do subproduto de supplier
AtD – AttributeDomain: atributo e domínio de valores acordados
A empresa compradora, após ter desencadeado o processo de resolução das restrições mútuas, fica à espera de ser notificada do padrão ConstraintTreaty com o campo client instanciado com a sua identificação. Esta mensagem, recebida dos dois fornecedores, assinala a conclusão do processo de negociação entre os fornecedores para a resolução das restrições impostas pelas suas propostas.
3.3.2 Avaliação das propostas
As funções de avaliação das propostas utilizadas pela empresa consumidora são relativamente simples. Se a descrição do subproduto é quantitativa são utilizadas as fórmulas:
![]() [1]
[1]
![]()
![]() [2]
[2]
que consideram todos os atributos que integram o subproduto. A melhor proposta, para cada subproduto, é a que maximiza o valor da função
de avaliação f da expressão [1].
Nestas fórmulas k é o número de atributos que constituem cada subproduto, Uti é a utilidade associada ao atributo i e a diferença dif(Vi,Vpi) quantifica, para o atributo i, o grau de aceitabilidade do valor Vi proposto – na realidade dif(Vi,Vpi) é a diferença normalizada entre a classificação atribuída ao valor Vi e a classificação do valor preferido Vpi:
![]() =
=
![]() [3]
[3]
No cálculo da diferença normalizada (fórmula [3]) u(Vi) é a classificação atribuída ao valor Vi e u(Vpi) é a classificação atribuída ao valor preferido do atributo i, uMAX(Di) é o valor da classificação máxima e umin(Di) é o valor da classificação mínima que podem existir para os valores do atributo i.
Se a descrição do subproduto é qualitativa a avaliação é feita recorrendo à fórmula [ROC00]:
![]() [4]
[4]
![]() , onde [5]
, onde [5]
![]() =
=
![]() , se o domínio é contínuo [6]
, se o domínio é contínuo [6]
![]() =
=
![]() , se o domínio é discreto [7]
, se o domínio é discreto [7]
A melhor proposta é a que maximiza o valor da função de avaliação f.
Nesta fórmula k é o número de atributos que constituem o subproduto e dif(Vi,Vpi) define o grau de aceitabilidade do valor Vi proposto relativamente ao valor preferido Vpi para o atributo i – também aqui dif(Vi,Vpi)representa a diferença normalizada entre os valores Vi e Vpi. A classificação atribuída ao valor proposto do atributo é função do domínio de valores possíveis para o atributo (descritos em 3.2.2). Vmaxi e Vmini são os valores extremos que o atributo i pode ter, se o domínio for contínuo. Se o domínio for discreto N é o número de valores possíveis para o atributo i, Pos(Vi) e Pos(Vpi) são as posições relativas dos valores Vi e Vpi no domínio. Como nesta descrição os atributos são ordenados por ordem crescente o seu peso é introduzido no expoente do cálculo do desvio.
Em cada ronda de negociação a proposta seleccionada, para cada subproduto, é aquela que apresenta melhor função de avaliação (máximo na descrição qualitativa, mínimo na descrição quantitativa) pois é a que mais se aproxima dos valores desejados para os atributos do subproduto. A melhor proposta é comparada, então, com a melhor proposta da última ronda e a melhor das duas é adoptada como sendo a ganhadora desta ronda.
De entre todas as propostas são encontrados os melhores valores propostos para cada atributo. A resposta a cada proposta, além de indicar se é ganhadora ou perdedora, também inclui a classificação relativa de cada atributo. O valor proposto para cada atributo é comparado com o melhor valor encontrado sendo-lhe atribuída uma classificação baseada na proximidade relativamente a este valor. Seguindo o modelo adoptado em [ROC00], a comparação distingue-se em três valores – próximo, afastado ou longínquo do melhor valor apresentado. Para isso são definidos dois valores d1 e d2 (d1 < d2) e, para todos os atributos de todas as propostas perdedoras, calcula-se a diferença normalizada entre o valor dos atributos dessas propostas e o valor do mesmo atributo na proposta ganhadora: Se a diferença for inferior a d1 a razão é próxima, se estiver entre d1 e d2, a razão é afastada e se for superior a d2 a razão é longínqua. Estas razões são incluídas na resposta (campo reason da lista de atributos - LAr- da classe ProposalReply).
Os agentes fornecedores que receberem esta informação irão tentar formular novas propostas para gerar a próxima ronda. A negociação termina quando o agente consumidor receber uma proposta cujo valor da função de avaliação o satisfaça ou, quando expirar o prazo de negociação, existir uma proposta com um valor aceitável para a função de avaliação. Está previsto o caso de o agente consumidor recusar estabelecer acordo com qualquer dos possíveis fornecedores e não se chegar a formar a empresa virtual.
3.3.3 Formulação das propostas
No anúncio inicial do subproduto a adquirir, são incluídas as preferências do consumidor – na descrição do subproduto, os atributos contêm o domínio de valores possíveis, o valor preferido e a importância desse atributo para o consumidor. Em face disso qualquer fornecedor, que também tem para os mesmos atributos o seu domínio de valores possíveis, o seu valor preferido e a sua importância relativa, pode avaliar a situação e tentar fazer boas propostas. Neste processo, o fornecedor tem que pesar dois valores muitas vezes antagónicos ou, pelo menos, não coincidentes – os seus próprios interesses como fornecedor e os interesses do consumidor. Para tentar maximizar os seus ganhos, o fornecedor poderá produzir propostas que não são as suas melhores propostas (vendo apenas o seu ponto de vista) mas que supõe serem as melhores do ponto de vista de satisfação dos interesses do consumidor. Este método de formulação de propostas leva o fornecedor a caminhar de uma actuação muito ambiciosa (maximizando apenas os seus lucros) para uma actuação menos ambiciosa (reduzindo os seus lucros na perspectiva de aumentar a satisfação do consumidor) [OLI99]. A obtenção do valor máximo para a combinação linear de duas funções genéricas não lineares é um problema complexo de optimização que pode socorrer-se de algoritmos genéticos para a sua solução. Neste sistema adoptou-se uma filosofia simples de tentativas sucessivas de melhorar a utilidade do consumidor e diminuir os lucros do fornecedor, de acordo com o resultado das propostas. Um método mais sofisticado é descrito em 3.3.5.
3.3.4 Resolução do problema da satisfação das restrições
Para a resolução do problema da satisfação de restrições seguiu-se a proposta apresentada no trabalho de Oliveira e Rocha [OLI00] onde é apresentado um algoritmo de resolução de restrições distribuídas que tenta encontrar uma solução global que satisfaça todas as restrições e, ao mesmo tempo, seja óptimo para as organizações envolvidas.
Após estar resolvida a questão da formação da empresa virtual, o agente consumidor põe em contacto as empresas fornecedoras que têm atributos restringidos. Estas empresas têm de negociar entre si para acordar nos valores admissíveis para os atributos restringidos. A solução final deverá ser comunicada ao agente consumidor.
A proposta inicial de cada agente é a sua melhor solução local - chamemo-lhe solução s*. Para tentar resolver o problema das restrições e chegar a um acordo, cada agente muda a sua solução local escolhendo uma solução sk (pior, necessariamente, que s*) que fará diminuir o valor da sua utilidade, se comparada com a melhor solução local. A esta diferença chama-se decréscimo do valor da utilidade do agente (duk) e será calculada como a diferença entre o valor das funções de avaliação de ambas as soluções [OLI00]:
duk = f(s*) – f(sk) [8]
A nova solução local sk será enviada ao outro agente juntamente com o valor do decréscimo da sua utilidade duk. Os agentes tentarão encontrar uma solução que minimize o decréscimo do valor da utilidade global (ou seja, o valor mínimo para a soma do decréscimo da utilidade local de cada agente). A negociação para a resolução das restrições termina quando esta solução for encontrada e for enviada para o agente consumidor.
O procedimento a adoptar será então:
(1) Um agente B recebe, na mensagem ConstraintNegotiation, uma lista de soluções, que é a mais favorável para quem a enviou (agente A), e onde estão indicados os respectivos decréscimos de utilidade locais. O agente B calcula o decréscimo global de utilidade em cada uma das soluções recebidas e envia-as de volta ao agente A com os decréscimos de utilidade totais.
(2) De entre todas as soluções locais possíveis ainda não seleccionadas, o agente B escolhe a melhor e calcula o decréscimo de utilidade local.
(3) O agente B escolhe entre a melhor solução obtida em (1), a solução obtida em (2) e a melhor solução alguma vez proposta no passado – a solução que apresentar menor valor para o decréscimo de utilidade é a escolhida. Nesta comparação há que atender a um aspecto importante – as soluções (1) e as do passado têm o valor do decréscimo de utilidade global e a solução obtida em (2) tem o valor do decréscimo de utilidade local. Se a solução que apresenta menor valor para o decréscimo de utilidade for a obtida em (2) é enviada para o agente A uma mensagem ConstraintNegotiation com a solução proposta e o processo de negociação prossegue - volta a (1). Se a solução que apresenta menor valor para o decréscimo de utilidade for uma do passado ou de (1), então esta é a solução final (minimiza o decréscimo de utilidade global dos agentes). Neste caso é enviada uma mensagem ConstraintAccordance para o agente A e o processo de resolução do problema das restrições termina.
(4) Ambos os agentes enviam para o agente consumidor a mensagem ConstraintTreaty com o resultado do acordo alcançado.
Este método simples assegura a privacidade das organizações envolvidas, na medida em que não são revelados, ao outro agente, todos os valores do domínio possíveis nem as utilidades reais desses valores. Apenas são trocados desvios à utilidade.
3.3.5 Aprendizagem
Para a formulação das propostas, Rocha [ROC00], Oliveira [OLI00] e Cardoso [CAR00] propõem usar a aprendizagem por reforço [SUT98] como método para capacitar o agente a aprender ao longo do processo de negociação e, se necessário, alterar a sua estratégia se houver alterações significativas no mercado.
Os sistemas de aprendizagem por reforço (reinforcement learning) aprendem a comportar-se num ambiente através de interacções do tipo tentativa e erro. A estas tentativas o ambiente responde com uma avaliação que traduz se a tentativa foi boa (bom valor de avaliação) ou má (mau valor de avaliação).
O algoritmo de aprendizagem por reforço Q-learning mapeia pares de valores estado/acção nos chamados Q-values. Quando um agente no estado actual s, executa a acção a, recebe um resultado r e atinge um estado s’, o Q-value correspondente é actualizado de acordo com a expressão [SUT98]:
![]() [9]
[9]
onde ![]() (factor de aprendizagem) e
(factor de aprendizagem) e
![]() (factor de desconto)
(factor de desconto)
O factor de desconto é utilizado para diminuir o peso dos reforços recebidos no futuro. Faz com que os reforços imediatos tenham mais peso que o futuros.
Um dos dilemas que os agentes enfrentam (à semelhança dos seres humanos) é escolher o tipo de actuação face a determinadas situações específicas – deve escolher a mais evidente ou explorar algo de novo? Se se optar por uma estratégia gradual podem perder-se algumas oportunidades de negócio por variações do próprio mercado. Pelo contrário se se optar por fazer muitas explorações os resultados podem ser desastrosos. Para assegurar que é feita alguma exploração de novos estados devem escolher-se acções com altos valores de Q-values (explorações de Boltzmann):
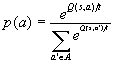 , onde
, onde
![]() (temperatura)
[10]
(temperatura)
[10]
p(a) é a probabilidade de escolher a acção a e t é um parâmetro que controla a quantidade de explorações a fazer (é decrementado ao longo do tempo para diminuir as explorações). Quanto t é elevado quase todas as acções são escolhidas com a mesma probabilidade. Quando o valor de t é baixo as acções com maior avaliação são mais vezes escolhidas.
No caso presente a fórmula de exploração de Boltzmann é adaptada para apenas explorar as acções possíveis (conjunto A) de acordo com as respostas do agente consumidor às propostas anteriores.
Se definirmos um estado como um conjunto de valores possíveis dos atributos para um subproduto:
s = (V1, V2, ... Vn) , Vi é o valor do atributo i
o estado representa uma proposta enviada para o consumidor.
Se definirmos uma acção pelo n-uplo:
a = (A1,
A2, ... An) ,
Ai ![]() {aumentar, diminuir,
manter}
{aumentar, diminuir,
manter}
os atributos com domínios discretos são incrementados (decrementados) movendo para o próximo (anterior) elemento do domínio, enquanto os atributos com domínios contínuos são incrementados (decrementados) de quantidades pré-definidas.
Quando um agente fornecedor recebe do agente consumidor a resposta (classe ProposalReply) a uma proposta (a proposta representa o estado s que resultou da acção ap no estado sp), tenta formular uma nova proposta seguindo os passos seguintes:
(1) Calcular o prémio da proposta anterior (que também define o estado s) de acordo com a classificação qualitativa recebida na mensagem de resposta (campo reason da lista de atributos - LAr- da classe ProposalReply):
![]() ,
se ganhadora
,
se ganhadora
![]() , se não ganhadora ,
, se não ganhadora , ![]()
Na fórmula anterior, penalty é um parâmetro que diminui o valor do prémio para as propostas com má avaliação pelo agente consumidor. Este parâmetro é definido para cada agente empresa de acordo com o seu próprio critério e o seu valor deve aumentar com o resultado da avaliação (próximo, afastado ou longínquo).
(2) Actualizar o Q-value do par estado/acção (Q(sp,ap)) usando a fórmula [9].
(3) Guardar o estado actual s, e o valor do prémio associado r.
(4) Calcular todos as novas acções promissoras a’ considerando esta mensagem de resposta. Por exemplo se a mensagem avaliou o atributo_1 como afastado uma possível acção a tomar é aproximá-lo mais do valor desejado e manter os outros. Guardar pares s/a’ com um valor de defeito para Q-value (Q(s,a’) = default).
(5) Mudar para o estado s*.
(6) Escolher a acção a* que tem o valor de probabilidade mais elevado, de acordo com a fórmula de exploração de Boltzmann [10] (as acções nunca tentadas estão guardadas no estado s* com o valor Q-value = default).
(7) Executar a acção a* e enviar nova proposta (estado) para o agente consumidor.
4 Implementação
Como foi referido na secção 3.1, o sistema VESM utiliza a linguagem de programação Java, a infra-estrutura para o sistema distribuído Jini e o serviço JavaSpaces como infra-estrutura de comunicações. São apresentadas, de seguida, estas ferramentas.
4.1 JAVA
Quando foi apresentada, em 1995, a linguagem Java [JAV9xA] provocou uma autêntica tempestade na Internet. Com o lançamento da versão 1.1, no início de 1997, os interpretadores Java quase duplicaram a velocidade e foram incluídas bastantes novas funcionalidades. Com a inclusão de acesso a bases de dados, objectos remotos, modelo de componentes de objectos, internacionalização, encriptação, assinaturas digitais, JavaBeans e outras tecnologias há quem admita que a linguagem Java ficou com o equilíbrio necessário para provocar uma revolução nas outras linguagens de programação [FLA97]. A versão 1.2 (também designada Java 2), lançada em finais de 1998, melhorou muito os aspectos de segurança, introduziu gráficos 2D, componentes Swing, Java IDL e referências permanentes a objectos. Apesar de todo o barulho que rodeia o Java 2 é importante recordar que, no seu núcleo, Java é apenas mais uma linguagem de programação, e a sua API é apenas uma biblioteca de classes como em outras linguagens. O que é interessante na linguagem Java, e é a fonte de toda a expectativa, é que contém um número de características importantes que a tornam especialmente vocacionada para programar em ambientes heterogéneos de rede, o que acontece principalmente neste final de século.
4.1.1 Características Básicas
Java é uma linguagem simples, orientada ao objecto, distribuída, interpretada, robusta, segura, independente da arquitectura, portável, com alto desempenho, multithreaded e dinâmica.
4.1.1.1 Orientada ao Objecto
Como programador isto significa que toda a atenção é centrada nos dados de uma aplicação e métodos que os manipulam, em vez de pensar estritamente em procedimentos.
Em linguagens orientadas ao objecto uma classe é um conjunto de dados e métodos que operam sobre esses dados. Juntos descrevem o estado e o comportamento de um objecto. As classes são estruturadas hierarquicamente permitindo que uma subclasse herde características da sua super-classe. Toda a hierarquia tem uma classe de raiz que, normalmente, é uma classe com um comportamento muito genérico.
A linguagem Java é um conjunto extenso de classes, organizadas em pacotes (packages), que se podem usar em programas. A classe Object (package java.lang) é a raiz da hierarquia Java.
Como a linguagem Java foi desenvolvida de raiz para ser orientada ao objecto tudo em Java são objectos: as únicas excepções são os tipos booleano e carácter. Como as classes são a unidade básica resultante da compilação do código, tudo em Java são classes.
4.1.1.2 Interpretada
O compilador Java gera bytecodes para a máquina virtual Java (Java Virtual Machine – JVM) em vez de código nativo. Para executar uma aplicação Java é necessário usar o interpretador Java. Como os bytecodes são independentes da plataforma, os programas Java podem correr em qualquer plataforma para a qual a JVM tenha sido portada.
Numa linguagem interpretada a fase de link de um programa desaparece. A fase de link de um programa Java, se se lhe pode chamar assim, é o processo de carregar novas classes para o ambiente à medida que forem sendo necessárias, processo incremental que ocorre em runtime.
4.1.1.3 Independente da Arquitectura e Portável
Porque os programas Java são compilados para um formato bytecode independente da arquitectura, uma aplicação Java pode correr em qualquer sistema desde que este implemente uma JVM. Isto é particularmente importante para aplicações distribuídas na Internet e noutras redes heterogéneas. Esta abordagem é também muito útil para as aplicações que têm de correr em múltiplas plataformas, por exemplo, correr em PCs, Macs ou workstations Unix. Com as variantes de Unix, Windows 95/98, Windows NT/2000 e Linux nos PCs e PowerPC nos Macintosh, é cada vez mais difícil produzir software para todas as plataformas possíveis. Aplicações escritas em Java, contudo, correrão em todas as plataformas.
O facto da linguagem Java ser interpretada e definir um formato bytecode normalizado, independente da arquitectura, é um aspecto muito importante para a portabilidade, pois não há aspectos dependentes da implementação das JVMs. Na especificação da linguagem estão explicitamente indicados os tamanhos de cada tipo primitivo de dados assim como o seu comportamento aritmético. Não existe, como na linguagem C, a possibilidade de um inteiro ter 16, 32 ou 64 bits dependendo da plataforma – em Java um inteiro tem sempre 32 bits.
4.1.1.4 Dinâmica e Distribuída
Qualquer classe Java pode ser carregada para um interpretador em qualquer altura, o que permite instanciação dinâmica.
Por ser uma linguagem distribuída fornece um alto nível de suporte para aplicações em rede. Por exemplo a classe URL e as existentes no package java.net tornam quase tão simples ler um ficheiro ou recurso remoto como um ficheiro local. Ao mesmo tempo o Remote Method Invocation (RMI) permite invocar métodos em objectos remotos, como que sejam objectos locais.
A natureza distribuída do Java é realmente brilhante quando combinada com a capacidade de carregamento dinâmico de classes. Estas características juntas tornam possível ao interpretador Java carregar e correr código através da Internet. É o que acontece quando um visualizador Web carrega e corre um applet Java.
4.1.1.5 Simples
A simplicidade desta linguagem advém do facto de os seus criadores pretenderem uma linguagem fácil de aprender e com um número reduzido de construtores, assim como fazer a linguagem parecer familiar à maioria dos programadores para migração fácil das aplicações. É visível, para os programadores de C e C++, que a linguagem Java utiliza muitos dos construtores das linguagens C e C++.
Contudo algumas das instruções destas linguagens foram deliberadamente removidas, aquelas que permitem uma programação pobre ou que raramente são usadas. O Java não utiliza ficheiros header, o que elimina o pré-processador C. Porque é orientada ao objecto, os construtores union e struct foram eliminados. A herança múltipla e o overloading de operadores, existentes em C++, foram abolidos.
A simplificação mais importante do Java foi, talvez, a abolição dos ponteiros, certamente a maior fonte de erros dos programas C e C++. Como não existem estruturas e os arrays e strings são objectos, não há necessidade de definir ponteiros. A referenciação de objectos é manipulada automaticamente pela linguagem Java. Além disso o Java implementa a recolha automática de lixo (garbage collection), deixando o programador de preocupar-se com ponteiros pendentes, referências inválidas ou perdas de memória, dedicando assim mais tempo às funcionalidades do programa.
4.1.1.6 Robusta
A linguagem Java foi concebida para escrever código altamente fiável e robusto. Como é uma linguagem fortemente tipificada permite que quase todos os erros sejam encontrados durante a fase de compilação. O Java obriga à declaração explícita dos métodos, o que permite ao compilador encontrar erros na invocação de métodos e torna, à partida, os programas mais fiáveis.
A falta de ponteiros e de aritmética com ponteiros aumenta a robustez da linguagem Java ao evitar todos os erros relacionados com ponteiros – todos os acessos a arrays e strings são verificados em runtime, assegurando que estão dentro dos limites e eliminando a possibilidade de sobrescrever posições de memória e corromper dados. A limpeza automática de lixo que o Java implementa liberta o programador das “tarefas mundanas de limpeza da casa”, geralmente associadas à gestão de memória, e evita alguns erros relacionados com a locação e libertação de memória.
O tratamento de excepções é outra das características que torna o Java uma linguagem robusta. Uma excepção é um sinal de que alguma condição excepcional aconteceu. Usando a instrução try/catch/finally pode agrupar-se o tratamento de erros num só sítio, simplificando a tarefa de manipulação e recuperação de erros.
4.1.1.7 Segura
Sem uma garantia de segurança certamente ninguém descarrega código de um local desconhecido da Internet e o deixa correr no seu computador, que é o que diariamente acontece quando se instala um applet. São disponibilizados vários níveis de segurança que permitem ao utilizador correr confortavelmente programas que não conhece, como applets.
Num nível mais básico a segurança anda de mãos dadas com a robustez. Como os programas Java não utilizam ponteiros não há a possibilidade de corrupção de memória – é uma primeira defesa contra código mal intencionado ou mal construído. Ao não permitir acesso directo à memória um grande número de possíveis ataques é evitado.
Um segundo nível de segurança contra código mal intencionado é o processo de verificação do bytecode que o interpretador Java executa sobre qualquer código que carregue. Esta verificação assegura que o código é bem feito – não permite overflow ou underflow da stack nem contém bytecodes ilegais.
Uma terceira camada de segurança é designada como modelo “caixa de areia” (sandbox): código não confiável é colocado nesta caixa onde pode correr à vontade pois está isolado do “mundo real”. Quando um applet está a correr numa caixa destas, existem grandes restrições ao que ele pode fazer. A maior delas é que não tem acesso ao sistema local de ficheiros. Estas restrições são controladas pela classe SecurityManager. Todas as classes Java que executam operações sensíveis pedem permissão ao SecurityManager instalado. Se a chamada for feita, directa ou indirectamente, de código não confiável é gerada uma excepção pelo gestor de segurança e a operação é abortada.
É possível adicionar uma assinatura digital ao código Java – a origem deste código pode ser verificada de um modo criptográfico seguro e único.
É evidente que a segurança não é uma coisa preta-e-branca. Como um programa não pode ser garantido 100% livre de erros, nenhuma linguagem ou sistema pode ser garantidamente 100% seguro.
Mais aspectos de segurança pode ser lidos na secção 4.1.2.
4.1.1.8 Bom Desempenho
Sendo uma linguagem interpretada o Java nunca será tão rápido como a linguagem C, uma linguagem compilada. Contudo é suficientemente rápida para aplicações interactivas, com interfaces ao utilizador gráficas e aplicações baseadas em rede, onde as aplicações estão a maior parte do tempo à espera que o utilizador faça qualquer coisa ou que a rede forneça dados.
Os interpretadores Java actuais já incluem compiladores just-in-time que traduzem os bytecodes para código nativo de um CPU particular em runtime.
Para comparar desempenhos é bom situar a linguagem Java no espectro das linguagens existentes. Num extremo estão as de mais alto nível, linguagens de scripting totalmente interpretadas, como as shells do Unix ou o Tcl. São linguagens fortemente prototipadas e muito portáveis, mas também muito lentas. No outro extremo temos linguagens compiladas de mais baixo nível, como o C e o C++. Estas linguagens têm um alto desempenho, mas sofrem em termos de portabilidade e fiabilidade. A linguagem Java fica no meio do espectro – o desempenho é muito superior às linguagens de scripting e oferece a simplicidade e portabilidade daquelas linguagens.
4.1.1.9 Multithreaded
A linguagem Java fornece suporte para múltiplos threads de execução (também chamados processos leves) que podem manipular diferentes tarefas. Um benefício importante do multithreading é aumentar o desempenho interactivo de aplicações gráficas.
Realizar threads em C ou C++ pode ser complicado. A linguagem Java fornece suporte inato para threads, o que facilita em muito a programação. O package java.lang fornece a classe Thread que suporta métodos para iniciar e parar threads e definir prioridades de threads, entre outras coisas. A sintaxe da linguagem permite sincronizar directamente os threads através da directiva synchronized. Basta esta directiva para marcar secções de código ou métodos para correr de modo exclusivo num único thread.
4.1.2 Arquitectura de Segurança
O modelo original de segurança da plataforma Java, conhecido como o modelo “caixa de areia” (sandbox) previa um ambiente restrito para correr código desconhecido obtido da rede. Neste modelo, mostrado na Figura 11, o código local tem acesso a todos os recursos do sistema mas o código remoto (um applet) só acede aos recursos que estão na sandbox. Um gestor de segurança (Security Manager) é responsável por determinar que recursos estão acessíveis a partir da sandbox.
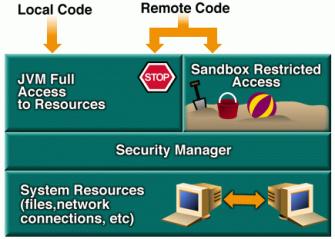
Figura 11 - Modelo de Segurança Java 1.0
A versão 1.1 introduziu o conceito de “applet sinalizado” como é mostrado na Figura 12. Um applet sinalizado digitalmente é considerado como código local, com acesso a todos os recursos do sistema, se a chave pública usada para confirmar a assinatura digital for verdadeira. Applets não sinalizados continuam a correr na sandbox. Os applets sinalizados, e as respectiva assinaturas, são transmitidos como ficheiros JAR (Java ARchive).
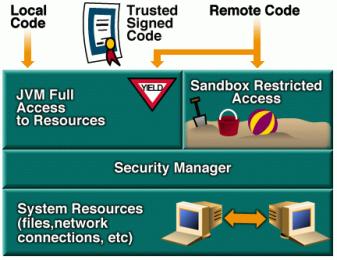
Figura 12 - Modelo de Segurança Java 1.1
A partir do Java 1.2 todo o código, seja local ou remoto, está sujeito a uma política de segurança. Esta política define um conjunto de permissões disponíveis para o código de vários autores ou locais e pode ser configurado pelos utilizadores ou pelo administrador do sistema. Cada permissão especifica o recurso acessível e o tipo de acesso – ler e escrever num determinado ficheiro ou directório, acesso a um determinado computador, etc.
O sistema organiza o código em domínios individuais, cada um dos quais engloba o conjunto de classes que têm o mesmo conjunto de permissões. A nova arquitectura de segurança está ilustrada na Figura 13. A seta da esquerda refere-se ao código que tem acesso a todos os recursos do sistema, a seta da direita refere-se ao código que tem o acesso mais restrito aos recursos do sistema (sandbox original). Todos os domínios intermédios têm mais permissão que o sandbox e menos que o acesso total.
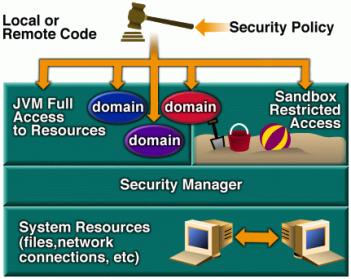
Figura 13 - Modelo de Segurança Java 1.2
Podem ainda existir extensões criptográficas.
4.1.3
RMI
(Remote Method Invocation)
Esta funcionalidade Java assume que existem aplicações formadas por dois programas separados: um servidor e um cliente. Uma aplicação servidor cria objectos remotos, torna acessíveis referências para eles e espera que clientes invoquem métodos nesses objectos remotos. Uma aplicação cliente pega na referência remota de um ou mais objectos do servidor e invoca métodos neles. O RMI fornece os mecanismos para a comunicação entre servidor e cliente e para a passagem de informação entre eles.
As aplicações distribuídas de objectos necessitam de:
Localizar objectos remotos: existem dois processos para obter referências de objectos remotos – a aplicação regista os seus objectos no RMI, através do rmiregistry, ou a aplicação envia e recebe a referência do objecto remoto como parte da sua operação normal.
Comunicar com objectos remotos: os detalhes da implementação entre os objectos remotos estão guardados no RMI; para o programador a comunicação remota é parecida com a invocação local de métodos.
Carregar os bytecodes dos objectos que circulam: porque o RMI permite passar objectos para objectos remotos, fornece os mecanismos necessários para carregar o código dos objectos ou apenas transmitir dados.
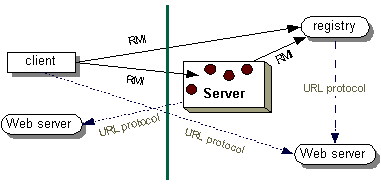
Figura 14 - Utilização do RMI registry
A Figura 14 mostra uma aplicação distribuída com RMI que usa o registry para obter a referência de um objecto remoto. O servidor invoca o registry para associar um nome com um objecto remoto. O cliente procura o objecto remoto pelo seu nome no registry do servidor e invoca um dos seus métodos. A figura também mostra que o RMI usa um servidor Web existente para transferir os bytecodes da classe do objecto, quando necessário, do servidor para o cliente e deste para o servidor.
4.1.4 Serialização
Existem duas classes Java, ObjectInputStream e ObjectOutputStream, pertencentes ao package java.io, que permitem ler e escrever objectos.
A forma de escrever um objecto é representando o seu estado numa forma serializada que permita a sua reconstrução à medida que for lido. Ler e escrever objectos é o chamado processo de serialização. A serialização é essencial para escrever aplicações transitórias e é usada de duas maneiras:
· RMI – comunicação entre objectos via socket.
· Persistência leve – arquivo de um objecto para posterior uso pelo mesmo ou outro programa.
4.2 JINI
O Jini é um conjunto de APIs e convenções que facilita a construção e o desenvolvimento de sistemas distribuídos “encarregado” de implementar as partes comuns. Ao contrário do que muita gente pensa Jini não é acrónimo de nada. Segundo um dos seus autores (Ken Arnold): “Jini Is Not Initials. É pronunciado da mesma forma que génio (em inglês ‘genie’)” [JIN99].
4.2.1 Visão Geral
A tecnologia Jini [ARN99][EDW99] é uma infra-estrutura simples para fornecer serviços numa rede e para criar interacções espontâneas entre programas que usam esses serviços. Os serviços podem juntar-se ou separar-se da rede de uma maneira robusta e os clientes podem ter confiança na disponibilidade dos serviços visíveis ou, em caso de falha, saber que esta é perfeitamente controlada. A interacção com um serviço é feita através de um objecto Java fornecido pelo próprio serviço. Este objecto é descarregado para o programa cliente que, assim, pode fazer uso do serviço mesmo que nunca tenha tido contacto anteriormente com o serviço – o objecto descarregado sabe como “falar” com o serviço.
Em poucas palavras isto é todo o sistema Jini. Estas ideias relativamente simples de explicar escondem uma grande potencialidade – permitem construir sistemas dinâmicos, flexíveis e robustos e constituídos por várias partes criadas independentemente por vários fornecedores.
4.2.2 Objectivos
A arquitectura Jini foi concebida para permitir disponibilizar um serviço numa rede a qualquer processo ou equipamento que o consiga descobrir, e fazer isso de uma maneira segura e robusta. Os seus objectivos são:
· Ligar e utilizar na rede (Network plug-and-work): permite juntar um serviço à rede e torná-lo visível e disponível para quem deseje utilizá-lo. Juntar o serviço à rede deve ser tudo, ou quase tudo, o que é necessário fazer para disponibilizar o serviço.
· Diluir a distinção entre hardware/software: o que um cliente deseja é um serviço – não é particularmente importante saber que parte do serviço é hardware e que parte do serviço é software desde que o serviço faça o que é desejado. Um serviço na rede deve estar disponível da mesma forma, e de acordo com as mesmas regras, quer seja implementado em hardware, quer seja implementado em software, quer seja uma combinação de ambos.
· Permitir conexão espontânea: quando os serviços são ligados à rede e estão disponíveis podem ser descobertos e utilizados por clientes ou por outros serviços. Quando clientes e serviços trabalham numa rede flexível de serviços podem organizar-se de forma mais apropriada para o conjunto de serviços disponíveis, em cada momento, no ambiente.
· Promover arquitecturas baseadas em serviços: com um mecanismo simples para colocar serviços na rede, mais produtos podem ser concebidos como serviços, em vez de aplicações isoladas.
· Simplicidade: esteticamente devemos fazer as coisas simples porque os sistemas simples dão-nos mais prazer. A maior parte do tempo de concepção é gasto na tentativa de retirar complexidade ao produto. Quando não se consegue retirar algo tenta-se inventar pedaços reutilizáveis para que uma ideia possa fazer o seu dever em vários sítios. O grande benefício do sistema resultante é que é mais fácil de aprender a usá-lo e de integrá-lo noutros sistemas a construir. Um sistema grande construído sobre princípios simples será mais robusto do que um sistema grande complexo.
4.2.3 Conceitos chave
O propósito da arquitectura Jini é federar grupos de equipamentos e componentes de software num único e dinâmico sistema distribuído. A federação resultante fornece simplicidade de acesso, facilidade de administração, partilha de recursos, fiabilidade e flexibilidade.
4.2.3.1 Serviços
O conceito mais importante dentro da arquitectura Jini é o de serviço. Um serviço é uma entidade que pode ser usada por uma pessoa, programa ou outro serviço. Um serviço pode ser uma operação, um espaço de memória, um canal de comunicação com um utilizador, um filtro de software, um equipamento hardware ou outro utilizador. Imprimir um documento ou reformatar um documento de um processador de texto para outro são exemplos de serviços.
Os membros de um sistema Jini constituem uma federação para partilhar serviços. Um sistema Jini não deve ser visto como conjuntos de fornecedores e clientes, utilizadores e programas ou programas e ficheiros – deve ser visto como um conjunto de serviços que podem reunir-se para realizar determinada tarefa. Os serviços podem usar outros serviços e um cliente de um serviço pode, por sua vez, ser um serviço com outros clientes. A natureza dinâmica de um sistema Jini permite que serviços sejam adicionados ou retirados da federação em qualquer altura de acordo com a procura, a necessidade ou a mudança de requisitos do grupo de trabalho que utiliza o sistema.
Num sistema Jini os serviços comunicam entre si através de um protocolo de serviço que é um conjunto de interfaces escritas em Java. Este é um protocolo sem limite onde o sistema base apenas define um pequeno número de interfaces para interacções críticas entre serviços.
4.2.3.2 Lookup Service
Os serviços são registados e encontrados através do lookup service. Este serviço é o mecanismo central do sistema e fornece o ponto de contacto entre o sistema e os seus utilizadores. Em termos precisos o lookup service mapeia interfaces que indicam as funcionalidades fornecidas por um serviço a um conjunto de objectos que implementam o serviço. Adicionalmente, entradas descritivas associadas a um serviço permitem uma selecção mais fina de serviços baseadas em propriedades entendíveis por pessoas.
Os objectos de um loookup service podem incluir outros lookup services, o que permite a construção de procura hierárquica. Além disso, um lookup service pode conter objectos que encapsulem outros directórios de nomes de serviços, permitindo a construção de pontes entre o Jini Lookup Service e outros tipos de lookup services.
Um serviço é adicionado a um lookup service através de um par de protocolos designados discovery and join – primeiro o serviço descobre a localização do lookup service apropriado (utilizando o protocolo discovery) e depois junta-se a ele (através do protocolo join).
4.2.3.3 Java Remote Method Invocation (RMI)
A comunicação entre os serviços é efectuada usando o Java RMI (secção 4.1.3). A infra-estrutura que suporta a comunicação entre os serviços não é, ela mesma, um serviço que se descobre e usa mas parte da infra-estrutura da tecnologia Jini. O RMI fornece mecanismos para encontrar, activar e limpar grupos de objectos remotos.
Fundamentalmente o RMI é uma extensão da linguagem Java que permite não só invocar métodos em objectos remotos como, também, passar dados entre objectos e mesmo objectos completos, incluindo código. Grande parte da simplicidade de um sistema Jini reside na possibilidade de mover código através da rede encapsulado como um simples objecto.
4.2.3.4 Segurança
A concepção do modelo de segurança para esta tecnologia assenta nas noções gémeas de principal e lista de acesso controlado. Os serviços são acedidos em nome de alguma entidade – principal – que, na generalidade, remete para um utilizador particular do sistema. Os serviços podem requerer acesso a outros serviços baseados na identidade do objecto que implementa o serviço. O tipo de acesso que é permitido a um serviço depende do conteúdo de uma lista de acesso controlado associada a cada objecto.
4.2.3.5 Leasing
O acesso à maioria dos serviços Jini é baseado na noção de aluguer (leasing). Um lease é a permissão de acesso garantido durante um período de tempo. Todo o leasing é negociado entre o utilizador do serviço e o seu fornecedor como parte do protocolo do serviço: um serviço é requisitado por determinado período; o acesso é permitido por determinado período, presumivelmente atendendo ao período pedido. Se um lease não for renovado enquanto está permitido – porque o recurso já não necessita dele, o cliente ou a rede falharam ou não é dada permissão para que seja renovado – então quer o utilizador quer o fornecedor do recurso concluem que o recurso está livre.
Os leases podem ser exclusivos ou não exclusivos. Se for exclusivo, é garantido que ninguém mais utiliza o recurso durante o período do leasing; se for não exclusivo, múltiplos utilizadores podem partilhar o recurso.
4.2.3.6 Transacções
Uma série de operações, pertencendo a um só serviço ou espalhadas por múltiplos serviços, podem ser ligadas numa transacção. As interfaces do Jini Transaction fornecem o protocolo necessário para coordenar o compromisso de duas fases (two-phase commit). A implementação das transacções, bem como a semântica da noção de transacção, é deixada à responsabilidade do serviço que usa essas interfaces.
4.2.3.7 Eventos Remotos
A arquitectura Jini suporta eventos distribuídos. Um objecto pode permitir a outros objectos registarem interesse em eventos desse objecto e receberem notificação da ocorrência de um dos eventos. podem assim escrever-se programas distribuídos baseados em eventos com garantia de fiabilidade e escalabilidade.
4.2.4 Componentes
Os componentes desta arquitectura podem ser divididos em três categorias: infra-estrutura, modelo de programação e serviços. A infra-estrutura é o conjunto de elementos que permite a construção de um sistema Jini federado, enquanto os serviços são as entidades dessa federação. O modelo de programação é um conjunto de interfaces que permite a construção de serviços fiáveis, incluindo os que fazem parte da infra-estrutura e os que se juntam à federação.
Estas três categorias, embora distintas e separáveis, estão de tal modo emaranhadas que a distinção entre elas pode não ser visível.
É possível construir sistemas com algumas das funcionalidades de um sistema Jini com variantes destas categorias ou mesmo sem alguma delas. Contudo um sistema Jini atinge todas as suas potencialidades quando construído com a infra-estrutura e o modelo de programação descritos, baseado na noção de um serviço. Desacoplar os segmentos dentro da arquitectura permite alterar minimamente código legado para fazer parte de um sistema Jini. Apesar de tudo, todas as potencialidades do Jini só se atingirão em serviços novos, construídos utilizando o modelo integrado.
4.2.4.1 Infra-estrutura
Esta infra-estrutura define o núcleo da tecnologia Jini, que inclui o seguinte:
· Sistema de segurança distribuído, integrado no RMI, que expande o modelo de segurança da plataforma Java para o mundo dos sistemas distribuídos.
· Os protocolos discovery and join, protocolos de serviço que permitem aos serviços(hardware ou software) descobrir, fazer parte e anunciar os serviços que podem fornecer a outros membros da federação.
· Lookup service – que funciona como um repositório de serviços. As entradas do lookup service são objectos Java que podem ser descarregados como parte de uma operação de procura e actuar como procuradores (proxies) locais dos serviços que colocaram o código no lookup service.
Os protocolos discovery and join definem o modo como qualquer serviço pode fazer parte de um sistema Jini; o RMI define a linguagem base através da qual os serviços Java comunicam; o modelo de segurança distribuído e a sua implementação definem o modo como as entidades são identificadas e como adquirem direitos de executar acções em seu nome ou em nome de outros; o lookup service reflecte os membros actuais da federação e funciona como um mercado central onde é possível aos membros da federação formar e encontrar serviços.
4.2.4.2 Modelo de Programação
A infra-estrutura descrita facilita o modelo de programação e faz uso dele. As entradas no lookup service são alugadas, permitindo ao lookup service reflectir com bastante fidelidade o conjunto de serviços disponíveis. Quando os serviços se juntam ou deixam o lookup service, são gerados eventos, e os objectos que registaram interesse nesses eventos são notificados quando novos serviços chegam ou quando serviços antigos deixam a actividade. O modelo de programação assenta na possibilidade de mover código, que é suportado pela infra-estrutura base.
Quer a infra-estrutura quer os serviços que a usam são entidades computacionais que existem no ambiente físico de um sistema Jini. Contudo, os serviços também constituem um conjunto de interfaces que definem protocolos de comunicação que, por sua vez, podem ser usados pelos serviços e pela infra-estrutura para comunicarem entre eles.
Estas interfaces reunidas fazem a extensão distribuída do modelo de programação da linguagem Java e constituem o modelo de programação Jini, ao qual se misturam:
· A interface de leasing, que define uma maneira de locar e libertar recursos usando um modelo temporal renovável.
· As interfaces de eventos e notificação, que são uma expansão do modelo de eventos usado pelos componentes JavaBeans para ambientes distribuídos, permitem comunicação baseada em eventos entre serviços Jini.
· As interfaces de transacções, que permitem a cooperação entre entidades de modo que ou todas as alterações feitas pelo grupo ocorrem atomicamente ou nenhuma ocorre.
A interface lease expande o modelo de programação da linguagem Java ao adicionar tempo à noção de reter a referência para um recurso, permitindo a correcção segura de referências quando há falhas de rede.
As interfaces de eventos e notificação permitem que eventos sejam manipulados por objectos de uma terceira parte, enquanto são garantidas as entregas e as temporizações. O modelo também prevê que a entrega de uma notificação distribuída seja atrasada.
A interface de transações introduz um leve protocolo orientado ao objecto para permitir às aplicações Jini coordenar mudanças de estado. O protocolo de transações coordena, em dois passos, as acções de um grupo de objectos distribuídos. O primeiro passo é a chamada fase de votação, durante o qual cada objecto ‘vota’ quando completa a sua parte da tarefa e está pronto para se comprometer com as alterações realizadas. No segundo passo o coordenador envia o comando de compromisso (commit) para cada objecto.
O protocolo de transacções Jini é diferente da maior parte dos mecanismos de transacções existentes pois assume que a transacção pode ser realizada fora de um sistema de processamento de transacções – esses sistemas tipicamente definem mecanismos e requisitos de programação que garantem a implementação correcta da semântica transaccional. O protocolo de transacções Jini aborda a questão com uma visão orientada ao objecto deixando nas mãos do implementador dos objectos envolvidos na transacção a correcta execução da transacção desejada. O objectivo do protocolo é definir as interacções que esses objectos devem ter para coordenar o grupo de operações.
As interfaces que definem o modelo de programação Jini são usadas pelos componentes da infra-estrutura quando apropriado e pelos serviços Jini iniciais. Por exemplo o lookup service utiliza as interfaces de eventos e de leasing – o leasing assegura que os serviços registados continuam disponíveis e os eventos ajudam na administração dos problemas de descoberta e dos equipamentos que precisam de configuração. O serviço JavaSpaces, descrito pormenorizadamente no capítulo 4.3, é um exemplo de serviço Jini que utiliza eventos e leasing e que suporta o protocolo de transacções. O gestor de transacções pode ser utilizado para coordenar a fase de votação de uma transacção para os objectos que suportem esse protocolo.
A implementação de um serviço Jini não obriga a usar o seu modelo de programação, mas esses serviços terão de usar o modelo para interagir com a infra-estrutura. Por exemplo, todos os serviços interagem com o lookup service através do modelo de programação e sempre que um serviço oferece recursos, numa base de leasing ou não, o seu registo no lookup service é alugado e, como tal, deve ser periodicamente renovado.
A ligação entre a infra-estrutura e o modelo de programação de serviços é o que distingue a federação de serviços Jini de uma mera colecção de serviços e protocolos. A combinação da infra-estrutura, serviços e modelo de programação, concebidas para trabalhar em conjunto e construídas usando-se mutuamente, simplifica o sistema e torna-o mais fácil de entender.
4.2.4.3 Serviços
Toda a tecnologia Jini (infra-estrutura e modelo de programação) assenta na disponibilização de serviços que podem ser oferecidos e encontrados na federação. Esses serviços utilizam a infra-estrutura para se invocarem mutuamente, descobrirem a sua localização e anunciar a sua presença a outros serviços e utilizadores.
Os serviços são objectos escritos em Java que podem fazer uso d outros objectos. Cada serviço tem uma interface que define as operações que podem ser efectuadas por esse serviço. Algumas interfaces são projectadas para serem usadas por programas, enquanto outras são projectadas para correr nos receptores de modo a que o serviço possa interagir com utilizadores. O tipo de serviço condiciona as interfaces que disponibiliza e define o conjunto de métodos que pode ser usado para aceder ao serviço. Como exemplos de serviços Jini temos:
· Serviço de impressão que pode imprimir a partir de aplicações Java ou de aplicações legadas.
· Serviço JavaSpaces que pode ser usado como um meio simples de comunicação ou como espaço de memorização de objectos escritos em Java.
· Gestor de transacções que permite a grupos de objectos participarem no protocolo de transacções Jini definido no modelo de programação.
4.2.5 Arquitectura de Serviço
Os serviços formam a base interactiva de um sistema Jini quer a nível de programação quer a nível de interface com os utilizadores. Os detalhes da arquitectura de serviços são mais facilmente entendidos depois de apresentados os protocolos Discovery and Lookup.
4.2.5.1 Protocolos Discovery e Lookup
O coração de um sistema Jini é o trio de protocolos descoberta, junção e procura (discovery, join e lookup). Quando se adiciona um equipamento ao sistema é usado o par discovery/join. O discovery acontece quando um serviço está à procura do lookup service no qual se irá registar. O protocolo join ocorre após o lookup service ter sido localizado e o serviço pretende juntar-se a ele. O protocolo lookup é usado quando um utilizador pretende localizar e invocar um serviço descrito pelas suas interfaces e, possivelmente, outros atributos.
Figura 15
- Protocolo Discovery
O Discovery/Join é o processo de adicionar um serviço a um sistema Jini. O fornecedor de serviço é o originador do serviço, quer seja um equipamento quer seja um programa de software. Primeiro o fornecedor do serviço tenta localizar um lookup service ao fazer um pedido multicast na rede local para que qualquer lookup service se identifique (discovery - Figura 15). Então um objecto de procuração do serviço (proxy) é descarregado para o lookup service (join - Figura 16). Este objecto de serviço contém a interface Java para aceder ao serviço, incluindo os métodos que os utilizadores e as aplicações invocarão para executar o serviço, juntamente com outros atributos descritivos.
Os serviços devem ser capazes de encontrar um lookup service mas podem delegar essa tarefa a uma outra entidade. A partir de agora o serviço está pronto para ser encontrado e usado, como mostra a Figura 17.
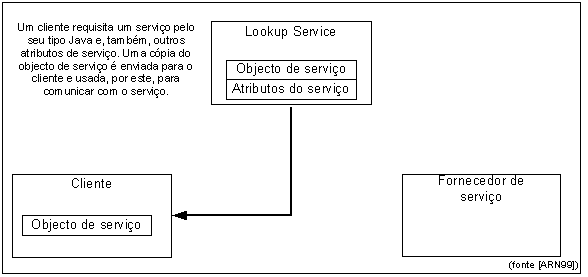
Um cliente localiza um serviço apropriado pelo seu tipo – interface na linguagem Java – e pelos atributos descritivos usados na interface utilizador do lookup service. O objecto de serviço é descarregado para o cliente. A fase final é a invocação directa do serviço, como se mostra na Figura 18.
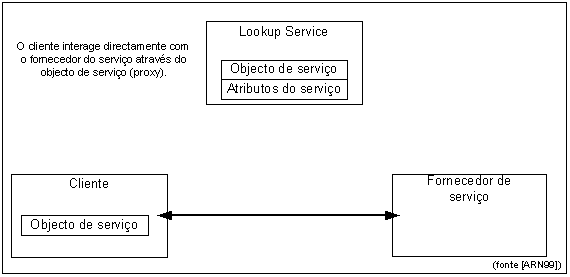
Figura 18 - Cliente usa o serviço
Os métodos do objecto de serviço podem implementar, e normalmente implementam, um protocolo privado com o fornecedor de serviço. Diferentes implementações da mesma interface de serviço podem usar protocolos de interacção completamente diferentes.
A possibilidade de transferir código entre o fornecedor do serviço e o lookup service e entre este e os clientes dá grande liberdade ao fornecedor de serviço para a comunicação com os clientes e garante que o objecto proxy, mantido pelos clientes, e o serviço que o forneceu estão sempre sincronizados. O cliente sabe que apenas está a lidar com uma implementação de uma interface escrita em Java e que o código que a implementa pode fazer o que for preciso para fornecer o serviço. Porque o código vem, originalmente, do próprio serviço, os detalhes de implementação do serviço apenas são do seu conhecimento.
As interfaces podem ser implementadas como referências RMI ao objecto remoto que implementa o serviço, como computação local que fornece todo o serviço localmente ou como combinação das duas. Estas combinações, também chamados smart proxies (procurações astutas), implementam algumas das funções do serviço localmente e as restantes como invocações remotas a uma implementação central do serviço. Uma interface utilizador pode ser guardada no lookup service como um atributo de um serviço registado. Assim é permitido a um utilizador do sistema manipular directamente o serviço.
Nas situações em que nenhum lookup service está disponível um cliente pode usar a técnica peer lookup (procura personalizada) – nesta situação o cliente pode enviar o mesmo pacote de identificação que é usado pelos lookup services para pedir aos fornecedores de serviços que se registem; estes, por sua vez, tentam registar-se no cliente como se de um lookup service se tratasse; o cliente pode, assim, seleccionar os serviços de que precisa a partir dos pedidos de registo e rejeitar os restantes.
4.2.5.2 Implementação de Serviços
Os objectos que implementam um serviço podem ser concebidos para correr num único espaço de endereços (ou Java Virtual Machine – JVM) quando existem requisitos de segurança para certos locais – são os chamados grupos de objectos. Um grupo de objectos reside sempre na mesma JVM quando corre. Os objectos que não pertencem a um mesmo grupo estão isolados correndo tipicamente, em JVMs diferentes.
Um serviço pode ser implementado directamente ou indirectamente em hardware especializado – neste caso os equipamentos são contactados pelo código associado à interface do serviço.
Do ponto de vista do cliente não há distinção entre um serviço implementado por objectos em equipamentos diferentes, serviços que são descarregados para a JVM local ou serviços implementados em hardware. Todos os serviços, estando disponíveis na rede, aparecem como objectos Java e desde que o seu funcionamento seja correcto, um tipo de implementação pode ser substituído por outro sem alteração ou conhecimento do cliente, desde que salvaguardadas as questões de segurança relacionadas com as permissões concedidas.
4.2.6 Diferenças entre Jini e RMI
Porque o Jini está construído sobre o RMI necessita deste para funcionar. Contudo o contrário não é verdadeiro – o RMI não necessita do Jini.
O RMI permite que clientes guardem referências de objectos noutras JVMs, invocar métodos nesses objectos remotos e passar objectos para e a partir desses métodos como parâmetros, valores de retorno e excepções. A capacidade do RMI passar objectos inclui um mecanismo que permite descarregar qualquer tipo de ficheiro através da rede para a JVM que recebe o objecto. O Jini permite a ligação espontânea de clientes e serviços numa rede, fazendo uso intensivo da capacidade do RMI enviar objectos através da rede.
Quer o Jini quer o RMI utilizam uma espécie de serviço de directório – no caso do Jini o directório é chamado lookup service, no caso do RMI é chamado registry. O lookup service do Jini permite a clientes retirar referências para serviços que chegam à JVM como referências para um serviço local que implementa uma interface de serviço. O registry do RMI permite aos clientes retirar referências para objectos remotos, que chegam à JVM local como referência para um fragmento (stub) de objecto que implementa a interface remota. Apesar das similaridades várias diferenças significativas existem entre os lookup services Jini e os registries RMI.
Em geral um programa cliente exige maior conhecimento acerca da rede se usar RMI do que se usar Jini, porque o Jini fornece um protocolo de descoberta que permite ao cliente localizar lookup services próximos sem prévio conhecimento das suas localizações. O RMI, por seu lado, obriga a que o cliente saiba onde o objecto remoto está instalado. Adicionalmente, como os fornecedores de serviços Jini também podem usar o protocolo de descoberta para localizar o lookup service, podem disponibilizar os seus serviços a toda a rede sem conhecimento prévio da sua composição. Devido ao protocolo discovery o Jini pode fornecer ligação espontânea à rede, o chamado ‘liga-e-funciona’ (plug-and-work) entre equipamentos. Porque lhe falta um protocolo tipo discovery o RMI não é tão espontâneo.
Outra diferença significativa entre o RMI e o Jini reside na diferença entre objecto de serviço (proxy) e fragmento de serviço (stub). Embora o Jini use o RMI para enviar objectos, o proxy onde o cliente invoca métodos não precisa de ser um stub RMI – pode ser mas não é obrigatório nem necessário. Um proxy Jini pode usar qualquer protocolo de rede, e não apenas RMI, para comunicar com qualquer servidor, equipamento ou o que possa estar na rede. Em alternativa pode mesmo implementar localmente o serviço completo sem necessidade de qualquer comunicação através da rede. No caso do RMI, os stubs utilizam sempre o protocolo RMI para comunicar, através da rede, com o objecto remoto. Na concepção de cada serviço Jini é decidido qual o protocolo (se for necessário) que será usado para comunicar entre o proxy local no cliente e o servidor remoto. Isto permite atingir o nível de abstracção dos sistemas distribuídos programando do nível de protocolo de rede para o nível de interface ao objecto. Os clientes não se preocupam com o protocolo mas apenas falam com interfaces a objectos.
A terceira diferença significativa entre o Jini e o RMI é que o Jini proporciona em modo muito mais expressivo de procurar serviços num lookup service do que o RMI proporciona a procura de objectos remotos no seu registry. Cada objecto remoto está associado, no registry, com um nome que é único. os serviços Jini são registados com identificadores de serviços, que são globalmente únicos e mantidos permanentemente por cada serviço, com proxies e com qualquer número de objectos de atributos. Os clientes podem procurar um serviço por identificador, pelo tipo Java ou tipos de proxies com igualdade exacta de atributos ou wildcards. Enquanto o RMI obriga o cliente a conhecer o nome através do qual o objecto remoto está registado, o Jini permite ao cliente procurar o serviço apenas por tipo de serviço. A possibilidade de procurar serviços por tipos Java é outra das facetas do Jini que possibilita a ligação espontânea em rede. Se nos ligarmos pela primeira vez a uma rede local e quisermos usar uma impressora, não é necessário saber qual o nome com que as impressoras de rede estão registadas, apenas procuramos serviços que implementem uma bem conhecida interface Printer. Procurar por tipo também assegura que os clientes Jini saberão usar o que quer que seja que retorne, pois têm de conhecer o tipo desejado, primeiro, para depois fazer a procura.
Em resumo, o propósito do RMI é permitir a invocação de métodos em objectos localizados em JVMs remotas e permitir enviar e receber objectos entre JVMs como parâmetros, valores de retorno e excepções na invocação daqueles métodos remotos. O propósito do Jini é permitir conexão espontânea de clientes e serviços que pretendem encontrar-se na mesma rede.
4.2.7 Diferenças entre Jini e CORBA
CORBA (Common Object Request Broker Architecture) [OMG89] é talvez mais como RMI do que Jini, mas o CORBA inclui um serviço trader que é algo reminescente do lookup service do Jini. O CORBA permite invocar métodos remotos escritos em qualquer linguagem de programação. O RMI permite invocar métodos em objectos Java localizados em JVMs remotas – os objectos podem não ter sido escritos em Java mas têm de correr numa JVM.
O CORBA tem um serviço de nomes que permite procurar um objecto por nome e obter uma referência remota para ele. O RMI tem um servidor de nomes (registry) que faz a mesma coisa: procura um objecto remoto por nome e obtém uma referência remota para ele. Contudo o CORBA distingue-se do RMI na maneira como usa a referência remota: para invocar métodos no stub local o CORBA obriga a que o cliente tenha uma definição prévia do stub localmente. Por outras palavras, CORBA obriga a que o objecto stub seja conhecido por quem desenvolve o cliente. O RMI, pelo contrário, pode enviar o código do stub através da rede e, por isso, não obriga a que os implementadores do cliente conheçam o código do stub.
O CORBA também oferece uma interface de invocação dinâmica que permite ao cliente usar objectos remotos sem a definição do stub, mas é muito mais complexo de usar do que invocar apenas métodos no stub local.
Outra diferença entre CORBA e RMI é que o RMI permite passar objectos por valor e por referência quando é invocado um método remoto. Até à especificação CORBA/IIOP 2.2, lançada em 1998, o CORBA apenas permitia passar objectos por referência. A especificação 2.2 incluiu suporte para passar objectos por valor mas esta funcionalidade ainda não se encontra na maioria das implementações CORBA existentes.
Outra diferença significativa entre CORBA e RMI é quando uma subclasse de um objecto é passada a um método remoto por valor – o CORBA trunca o objecto para o tipo declarado na lista de parâmetros do método. Por exemplo, se um método remoto espera um Animal e o cliente lhe passa um Gato (subclasse de Animal), o objecto remoto receberá um Animal (Gato truncado) e não um Gato. Porque o RMI pode enviar a definição da classe Gato através da rede, o objecto remoto RMI receberá um Gato. Se a máquina virtual remota não souber o que é um Gato, descarregará a definição da classe através da rede.
Como foi previamente mencionado, o CORBA inclui um serviço reminescente do lookup service do Jini: o serviço trader. Em vez de fornecer apenas um nome com o qual está associado um objecto remoto, como se faz no serviço de nomes do CORBA ou no registry do RMI, pode descrever-se o tipo de objecto que se procura, da mesma forma que se pode procura um serviço Jini por tipo. Contudo o lookup service do Jini oferece um pouco mais de flexibilidade, ao permitir incluir uma identificação global única e um conjunto de atributos na procura. Mas a maior diferença entre o serviço trader do CORBA e o lookup service do Jini está no que retornam como resultado da procura – o serviço trader do CORBA devolve uma referência para um objecto remoto que iguale a procura, enquanto o lookup service do Jini devolve um objecto proxy por igualdade de valor.
Assim, quando se obtém uma referência remota do serviço trader do CORBA (e assumindo que se tem a definição do stub) pode comunicar-se com o objecto remoto através da invocação de métodos no stub local – o stub local falará através da rede com o objecto remoto, via CORBA. Quando se obtém um objecto proxy através do lookup service do Jini, por outro lado, esse proxy pode não ter necessidade de falar através da rede com o objecto remoto – pode implementar o serviço completamente na máquina virtual do cliente., ou pode falar através da rede com um servidor, vários servidores, ou mesmo hardware, via sockets ou streams. Ou o proxy pode ser um stub RMI que comunica através da rede com um objecto remoto, via protocolo RMI. O proxy devolvido pelo Jini pode usar qualquer protocolo de rede para comunicar através dela, até mesmo CORBA.
4.3
JavaSpaces
A tecnologia JavaSpaces [FRE99] é um mecanismo simples unificado para comunicação dinâmica, coordenação e partilha de objectos entre recursos de rede, por exemplo entre clientes e servidores, baseado na tecnologia Java. Numa aplicação distribuída a tecnologia JavaSpaces actua como um “espaço” virtual de partilha de objectos ou recursos de rede entre fornecedores e consumidores - numa solução distribuída é permitido aos participantes trocar tarefas, pedidos e informação na forma de objectos Java. Esta tecnologia permite desenvolver soluções com capacidade para criar e guardar objectos com persistência, característica fundamental para manter a integridade de processos.
Esta tecnologia aparece como um serviço Jini que facilita a construção de aplicações distribuídas para a Internet e intranets.
O modelo JavaSpaces envolve “áreas” de troca de objectos persistentes, nas quais processos remotos podem coordenar acções e trocar dados. Proporciona a ubiquidade (omnipresença) necessária para o esqueleto da computação distribuída, emergindo como uma tecnologia chave neste campo.
4.3.1 Desafios da Computação Distribuída
Apesar dos seus benefícios (desempenho, escalabilidade, partilha de recursos, tolerância a falhas, disponibilidade e elegância) as aplicações distribuídas podem ser bastante difíceis de desenhar, construir e depurar. Escrever código para um ambiente distribuído é mais complexo do que escrever código para um ambiente isolado. A complexidade mais óbvia é a variedade de equipamentos, arquitecturas e plataformas de software que podem estar envolvidas. No passado esta heterogeneidade travou o desenvolvimento e a proliferação de aplicações distribuídas.
A realidade de um ambiente distribuído apresenta alguns desafios, para além da sua heterogeneidade intrínseca. Pela sua natureza as aplicações distribuídas são construídas a partir de vários componentes (potencialmente com falhas) que comunicam por ligações em rede (potencialmente lentas e sem redundância). Estas características levantam três tipos de problemas – latência, sincronização e falhas parciais.
Latência – Os processos de uma aplicação distribuída precisam de comunicar para colaborarem entre si. Infelizmente a comunicação através das redes é muito mais lenta do que os processadores onde corre o código. Este retardamento temporal, chamado latência, que se verifica nas comunicações entre dois processos a correr em equipamentos diferentes, é tipicamente bastante superior ao observado quando os processos estão a correr no mesmo equipamento. Ignorar este facto pode levar a construir aplicações com um desempenho muito baixo.
Sincronização – Para cooperar mutuamente, os processos de uma aplicação distribuída não necessitam apenas de comunicar – as suas acções têm de ser sincronizadas, por exemplo, para aceder e actualizar dados partilhados. Sincronizar processos distribuídos é complexo desde que os processos saiam verdadeiramente assíncronos, correndo em equipamentos distintos e comunicando sem qualquer controlador centralizado.
Falha parcial – É talvez o desafio maior que se enfrenta quando se desenham aplicações distribuídas – à medida que uma aplicação corre e inclui mais processos, maior é a probabilidade de um dos seus componentes falhar ou para a execução (por crash do equipamento ou por problemas de rede). Na perspectiva dos restantes participantes da aplicação distribuída, um processo falhado é simplesmente rotulado de “perdido em combate” e as razões para a falha não são, normalmente, determinadas. No caso de aplicações centralizadas, que correm sempre no mesmo equipamento, a falha parcial não é problema – se um componente falhar toda a aplicação falha e é necessário relançar a aplicação ou o próprio equipamento. Um sistema distribuído, por outro lado, deve adaptar-se graciosamente a cenário da falha parcial e é trabalho de quem desenvolve assegurar que a aplicação mantém um estado global consistente (tarefa muitas vezes complicada).
4.3.2 JavaSpaces – Um Novo Modelo de Computação Distribuída
A construção de aplicações distribuídas com as ferramentas convencionais de redes baseia-se em passar mensagens entre processos ou invocar métodos em objectos remotos. Nas aplicações JavaSpaces os processos não comunicam directamente mas coordenam as suas actividades trocando objectos através de um espaço - um processo pode colocar novos objectos e retirar ou copiar objectos de um espaço. A Figura 19 mostra vários processos (representados por Dukes) interagindo com um espaço utilizando estas operações. Quando retiram ou lêem objectos, os processos utilizam procura por identidade de valores (value-matching lookup), baseada no valor dos campos, para encontrar os objectos que lhes interessam. Se não for encontrada uma igualdade imediata com os objectos existentes no espaço, o processo pode esperar até que um objecto nessa circunstância chegue ao espaço. Ao contrário dos repositórios convencionais de dados, no JavaSpaces os processos não alteram os objectos guardados no espaço nem invocam os seus métodos directamente – enquanto estão no espaço os objectos são dados passivos. Para modificar um objecto um processo deve explicitamente retirá-lo, alterá-lo e tornar a inseri-lo no espaço.
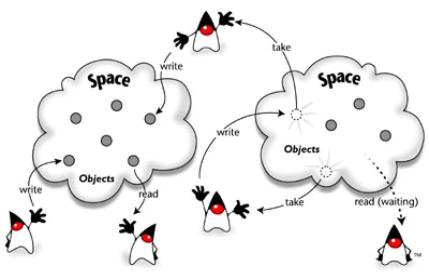
Figura 19 - Processos usam o espaço e operações simples para coordenar as suas actividades
Os espaços são repositórios de objectos com algumas propriedades importantes que contribuem para fazer do JavaSpaces uma ferramenta expressiva e poderosa. Vejamos:
Os espaços são partilhados: vários processos remotos podem interagir com um espaço de forma concorrencial – o espaço encarrega-se de manipular os detalhes do acesso concorrente, deixando o programador focalizado na tarefa de desenvolver o protocolo entre os processos.
Os espaços são persistentes: os espaços fornecem memorização fiável para os objectos. Quando um objecto é guardado num espaço permanece lá até ser retirado por alguém. Também se pode requerer um aluguer de espaço por determinado período temporal. Uma vez colocado no espaço o objecto manter-se-á até que o seu limite temporal (que pode ser renovado) expire ou um processo o retire do espaço.
Os espaços são associativos: os objectos no espaço são localizados por procura associativa, não por posição de memória ou por identificador. A procura associativa fornece um modo simples de encontrar os objectos nos quais se tem interesse, de acordo com o seu conteúdo, sem saber o seu nome, quem o criou ou onde está guardado. Para procurar um objecto é criado um padrão (template) – objecto com alguns campos (ou todos) preenchidos com determinados valores e os restantes deixados em branco para funcionarem como wildcards. Um objecto do espaço iguala o padrão se os campos preenchidos forem exactamente iguais. Com a procura associativa é muito fácil exprimir perguntas (queries) para objectos, como por exemplo, “Existem tarefas para executar?” ou “Há alguma resposta para a operação que eu pedi?”.
Os espaços são transaccionalmente seguros: o JavaSpaces utiliza o serviço de transações do Jini para assegurar que uma operação no espaço é atómica (ou a operação é integralmente executada ou não é executado nada). As transacções são suportadas para operações simples num espaço e também para múltiplas operações envolvendo um ou vários espaços (neste caso ou são executadas integralmente todas as operações ou nenhuma é executada). Este aspecto é muito importante para lidar com falhas parciais.
Os espaços permitem trocar código executável: enquanto num espaço os objectos são dados passivos – não é possível modificá-los nem invocar os seus métodos. Contudo, quando um objecto é lido ou retirado de u espaço é criada uma cópia local do objecto. Como qualquer objecto local é possível alterar os seus campos públicos e invocar os seus métodos. Esta capacidade proporciona um mecanismo poderoso para expandir o comportamento das aplicações através do espaço.
Estas propriedades são um ponto chave para criar aplicações distribuídas que funcionam bem num ambiente Jini, onde a ligação à rede é espontânea e os processos integram ou deixam a comunidade dinamicamente, muitas vezes devido a falhas dos equipamentos ou da rede.
4.3.2.1 Origem do JavaSpaces
Embora seja descrito como um novo modelo de computação distribuída a origem do JavaSpaces pode ser descoberta na Universidade de Yale, no início da década de 1980, nos trabalhos do dr. David Gelernter que desenvolveu uma ferramenta chamada Linda [GEL85] para construir aplicações distribuídas. Esta ferramenta combina um pequeno número de operações simples com uma memorização persistente chamada espaço de tuplos (tuple space). As operações são ortogonais para qualquer linguagem de programação: são parte de uma linguagem de coordenação que podem ser adicionadas a qualquer linguagem de computação. O resultado da investigação Linda foi surpreendente: usando um objecto de memorização (espaço de tuplos) com um pequeno número de operações simples, facilmente se pode implementar um vasto conjunto de problemas distribuídos e paralelos utilizando técnicas que aliviam muitos dos problemas de construir sistemas em rede. Por outras palavras, sistemas baseados em espaços são simples (poucas operações se realizam sobre eles) e expressivos (solucionam bem muitos dos problemas distribuídos). Este trabalho inspirou a equipa JavaSpaces da Sun Microsystems Inc. e influenciou também a concepção dos componentes de procura (lookup) e descoberta (discovery) da tecnologia Jini. Embora o JavaSpaces tenha herdado o modelo de espaço do Linda, o modelo foi melhorado em vários aspectos tirando partido do potencial dos objectos Java, RMI e serialização de objectos.
4.3.2.2 A API do JavaSpaces
Qualquer objecto guardado no espaço JavaSpace tem que implementar a interface Entry e, por isso, é também designado muitas vezes como entrada. A interface Entry não contém constantes nem métodos, bastando acrescentar implements Entry à definição das classes para as tornar potenciais participantes do espaço JavaSpaces.
Convém, no entanto, seguir algumas convenções para estas entradas. Uma entrada deve ter um construtor público sem argumentos (no-arg constructor) – isto deriva do processo de serialização que ocorre quando uma entrada é transferida de e para o espaço JavaSpaces. Outra convenção é que os campos de uma entrada devem ser declarados públicos, para permitir que outros processos encontrem as entradas por procura associativa baseada no valor dos campos. Uma terceira convenção advoga que numa entrada os campos devem conter referências para objectos e vez de tipos primitivos (por exemplo, se for necessário definir um campo do tipo inteiro deve usar-se a classe Integer em vez da primitiva int). Uma classe que implemente a interface Entry é como qualquer outra classe Java, podendo ser instanciada, invocar os seus métodos e atribuir valores aos seus campos.
Para interagir com um espaço é necessário obter acesso a um objecto que implemente a interface JavaSpace. Isso pode ser feito recorrendo ao Jini Lookup Service (secção 4.2.3.2) ou ao RMI Registry (secção 4.1.3). Qualquer objecto que implemente esta interface fornece os métodos que são toda a “filosofia” do JavaSpace:
· write: coloca uma cópia de uma entrada no espaço. Se for invocado várias vezes para a mesma entrada várias cópias são colocadas no espaço.
· read: a partir de uma entrada usada como padrão (template) retorna a cópia de um objecto do espaço que iguale o padrão. Se não existir qualquer objecto que iguale o padrão o read espera um tempo determinado pelo utilizador até que apareça algum objecto com as características desejadas.
· readIfExists: a mesma funcionalidade do read mas com retorno imediato. Se não existir nenhum objecto que iguale o padrão é retornada uma instância vazia.
· take: funciona como o read mas o objecto que iguala o padrão é retirado do espaço e retornado como resultado do take.
· takeIfExists: a mesma funcionalidade do take mas com retorno imediato. Se não existir nenhum objecto que iguale o padrão é retornada uma instância vazia.
· notify: a partir de um padrão e de um objecto é pedido ao espaço que notifique o objecto quando entradas que igualem o padrão forem adicionadas ao espaço. Este mecanismo de notificação, construído no modelo Jini de distribuição de eventos, é útil quando se programa reactivamente utilizando o espaço.
· snapshot: fornece um método para minimizar a serialização que ocorre sempre que um objecto é introduzido no espaço. É muito útil se a mesma entrada for introduzida várias vezes num espaço.
4.3.2.3 Construir Aplicações com o JavaSpaces
Para construir aplicações baseadas no JavaSpaces, devem ser concebidas estruturas distribuídas de dados e protocolos distribuídos que operam sobre os dados.
Uma estrutura distribuída de dados é um conjunto de múltiplos objectos guardados num ou em vários espaços. Por exemplo, uma lista ordenada de itens pode ser representada por um conjunto de objectos, cada um dos quais guarda o valor e a posição de um determinado item. A representação dos dados como uma colecção de objectos num espaço partilhado permite a vários processos aceder e modificar a estrutura de dados de forma concorrente.
Os protocolos distribuídos definem o modo como os participantes de uma aplicação partilham e modificam as estruturas de dados de uma forma coordenada. Por exemplo, se a lista ordenada anterior representar uma fila de tarefas para imprimir em várias impressoras, o protocolo deve especificar o modo como as impressoras se coordenam para evitar impressões duplicadas. O protocolo deve, também, manipular erros – se não for assim uma impressora encravada, por exemplo, pode obrigar vários utilizadores a esperarem desnecessariamente pelo fim de um trabalho, mesmo havendo mais impressoras disponíveis. Este exemplo simples é representativo dos vários problemas que os protocolos distribuídos mais evoluídos enfrentam.
Os protocolos distribuídos escritos para utilizar espaços têm a vantagem de ser muito levemente ligados – porque os processos interagem indirectamente através do espaço, os transmissores e os receptores dos dados podem não se conhecer e podem mesmo não estar activos simultaneamente. As ferramentas distribuídas tradicionais obrigam a que todas as mensagens sejam enviadas para um processo determinado (quem), num determinado equipamento (onde), num determinado momento (quando). Em vez disso com um sistema JavaSpace podem escrever-se objectos num espaço na expectativa que alguém, algures, em qualquer altura, retire o objecto e faça uso dele de acordo com o protocolo distribuído. Desacoplando transmissores e receptores obtêm-se protocolos mais simples, flexíveis e fiáveis. Pegando no exemplo das impressoras anterior, os pedidos de impressão podem ser colocados no espaço sem a preocupação de especificar uma impressora em particular ou sequer saber que impressoras estão a funcionar, pois quando uma estiver livre encarregar-se-á de retirar uma tarefa do espaço e imprimir o trabalho.
As características desta tecnologia encorajam a utilização de estruturas distribuídas de dados e simplificam o desenvolvimento de protocolos distribuídos.
4.4 Sistema VESM
A implementação do protótipo do sistema VESM foi realizada apenas numa rede local, mas o seu transporte para uma rede mais alargada é bastante simples.
4.4.1 Classes Java genéricas
As classes Java mais importantes já foram referidas durante a descrição da estrutura do sistema multi-agente (secção 3.2) e na negociação (secção 3.3).
Algumas classe genéricas utilizadas neste sistema são:
Condition (Cid, CV)
Cid – identificação da condição
CV – valor da condição
Uma das condições sempre presente durante a negociação é Deadline. Para esta condição o campo CV é uma instância da classe VEDate, e indica o tempo marcado como limite para o fim da negociação. Esta classe implementa um GregorianCalendar, é serializável, e possui um construtor vazio que dá o tempo actual GMT+DST (Greenwich Medium Time, Daylight Saving Time).
A classe AttributeDomain define o identificador de um atributo e o domínio de valores desse atributo :
AttributeDomain
(Atid, D)
Atid – identificação do atributo
D – domínio de valores possíveis (classe Domain)
A classe PartialSolution permite identificar as restrições impostas e passar valores durante a fase de satisfação de restrições. Para um subproduto contém os valores de determinado atributo:
PartialSolution (SPid, AtD)
SPid – identificação do subproduto
AtD – identificação do atributo e valores possíveis
(classe AttributeDomain)
A classe Solution também é usada durante a fase de satisfação das restrições e contém as soluções parciais (PartialSolution) dos dois fornecedores mais o decréscimo de utilidade global desta solução:
Solution (PSA, PSB, dU)
PSA – PartialSolution do fornecedor A
PSB – PartialSolution do fornecedor B
dU – decréscimo global da utilidade associada a esta
solução
A classe VELinkedList é uma lista ligada de listas ligadas, cada uma das quais com uma identificação – mantém, por exemplo, a lista de negociações activas de um agente empresa:
VELinkedList (Id, Llist)
Id – identificação da lista
Llist – lista ligada (classe LinkedList)
A classe VEPropRep agrupa a proposta e a resposta à proposta numa só classe. Serve para o agente empresa manter um registo histórico das suas negociações:
VEPropRep (proposal, reply)
proposal – proposta (classe Proposal)
reply – resposta à proposta (classe ProposalReply)
A classe XY é a mais genérica e é usada com um tuplo, ou par X/Y. Tipicamente guarda os pares valor/classificação de um domínio ou os pontos (x,y) num referencial cartesiano:
XY (x, y)
4.4.2 Configurações necessárias
As aplicações JavaSpaces interagem com um ou mais espaços. Por isso é necessário ter um espaço para a aplicação correr. Mas como o espaço JavaSpaces é um serviço Jini necessita desta infra-estrutura bem configurada:
- Um servidor HTTP, usado para descarregar o código dos clientes JavaSpaces;
- Um RMI Activation Daemon, que monitoriza o estado dos serviços, rearrancando os serviços que “crasham”, ou desactivando e reactivando serviços que não estão ou estão a ser usados;
- Um Lookup Service, para permitir aos clientes procurar e encontrar os serviços Jini disponíveis na rede local;
- Um serviço JavaSpaces, o nosso VESpaceMarket.
A partir daqui podem arrancar-se os agentes empresa e os agentes utilizador.
5 Conclusões e trabalho futuro
Neste trabalho foi realizado um estudo sobre as Empresas Virtuais e as suas formas de representação. Comparando as várias arquitecturas existentes desenvolvemos uma plataforma aberta para a formação de um mercado electrónico onde as empresas se dão a conhecer e estabelecem acordos para a formação de empresas virtuais (sistema VESM).
Foram feitas experiências nesta plataforma no sentido de avaliar e melhorar os protocolos de negociação descritos nos trabalhos de Rocha e Oliveira [OLI00][ROC00].
Os agentes de software podem automatizar muitas tarefas, tais como os processos de negociação multi-critério e de resolução de conflitos por propagação de restrições, com o objectivo de ajudar à formação de Empresas Virtuais.
As metodologias multi-agente oferecem a independência desejada para as empresas e a confidencialidade necessária para que a negociação se faça sem perda de autonomia.
A automação da negociação é, contudo, mais crítica porque implica a utilização de estratégias que irão determinar sucesso ou insucesso na integração de uma empresa como membro de uma EV. Além disso a confiança dos utilizadores nos agentes de software é a maior limitação à sua propagação, pois as limitações da Inteligência Artificial têm vindo a ser, progressivamente, ultrapassadas.
O desenvolvimento do sistema VESM permitiu criar uma plataforma completamente aberta e distribuída, que inclui a possibilidade de construção de agentes com diferentes estratégias de negociação. Para a sua utilização não são necessários grandes esforços de normalização e é permitido que diferentes empresas considerem diferentes descrições na apresentação dos produtos (descrição qualitativa ou quantitativa). Estas duas descrições foram ensaiadas no protocolo de negociação. Enquanto a descrição quantitativa oferece maior flexibilidade na classificação dos valores possíveis em cada atributo, maior coerência com a realidade e critérios claros, apresenta maior dificuldade na definição dos domínios, pode ser difícil a aproximação à realidade e pode exigir funções de avaliação bastante complexas. Por outro lado a descrição qualitativa é mais simples de configurar e tem funções de avaliação mais simples, mas oferece menor flexibilidade na classificação dos valores dos atributos (não permite, por exemplo, valores com igual classificação) e os critérios são sempre mais vagos.
Para o futuro pretende estudar-se um método que permita incluir restrições a outros subprodutos durante a fase de resolução de restrições. A aprendizagem na negociação, para tentar obter modelos das outras empresas, também é um caminho que pode ser explorado.
A configuração inicial de cada empresa é um trabalho um pouco pesado e cansativo – está em estudo a possibilidade de estender a linguagem Unilang, desenvolvida por Reis [REIS00] para descrever problemas de escalonamento, à descrição inicial das características e capacidades das empresas.
A aplicação de vários algoritmos de aprendizagem à negociação multi-critério, relacionando vários critérios entre si, pode ajudar a definir e implementar várias estratégias de negociação.
Referências
|
[AKEN98] |
Aken, J.E. van, ‘The Virtual Organisation: a special mode of a strong
interorganisational cooperation’, in: Managing Startegically in an
Interconnected World, Chichester: Jonh Wiley & Sons, 1998. (Citado em [BUL98]) |
|
[ARN99] |
Arnold, K.; O’Sullivan, B.; Scheifler, R.W.; Waldo, J.; Wolrath, A., ‘The Jini Specification (The Jini Technology Series)’, Addison-Wesley, 1999, ISBN 0-201-61634-3. |
|
[BAR94] |
Barbuceanu, M.; Fox, M.S., The Information Agent: An Infrastructure Agent Supporting Collaborative Enterprise Architectures, Proceedings of 3-rd Workshop on Enabling Technologies: Infrastructures for Collaborative Enterprises, Morgantown WV, IEEE Computer Science Press, 1994. [http://www.eil.utoronto.ca/papers/abstracts/1.html] |
|
[BARR98] |
Barry, J.; Aparicio, M.; Durniak, T.; Herman, P.; Karuturi, J.; Woods, C.;Gilman, C.; Ramnath, R., ‘NIIIP-SMART: An investigation of Distributed Object Approaches to support MES development and deployment in a Virtual Enterprise’, 2nd IEEE International Enterprise Distributed Computing Workshop (EDOC’98), November 2-5, 1998. |
|
[BAS97] |
Bastos, R.M., O Planejamento de Alocação de Recursos
Baseado em Sistemas MultiAgente, Proposta de tese de doutorado,
Universidade Federal do Rio Grande do Sul, Porto Alegre, Brasil, Setembro
1997. |
|
[BUL98] |
Bultje, R. and Wijt, J. van, ‘Taxonomy of Virtual Organisations, based on definitions, characteristics and typology’, KPN Research, The Netherlands, in virtual-organization.net, Newsletter, Vol.2, No.3, September 1, 1998. |
|
[BYRN93] |
Byrne, J.A., ‘The Virtual Corporation’, in Business Week, February 1993. (Citado em [BUL98]) |
|
[CAM97] |
Camarinha-Matos, L.M.; Carelli, R.; Pellicer, J.; Martin, M., ‘Towards the virtual enterprise in food industry’, Proceedings of ISIP’97, OE/IFIP/IEEE Int. Conf. on Integrated and Sustainable Industrial Production, Chapman & Hall (Re-Engineering for Sustainable Industrial production), Lisbon, Portugal, May 1997. |
|
[CAM99A] |
Camarinha-Matos, L.M.; Afsarmanesh, H., ‘The Virtual Enterprise Concept’, in Infrastructures for Virtual Enterprises (PRO-VE’99), L.M. Camarinha-Matos, H. Afsarmanesh (Eds.), Kluwer Academic Publishers, October 1999. |
|
[CAM99B] |
Camarinha-Matos, L.M.; Afsarmanesh, H., ‘Tendencies and General requirements for Virtual Enterprises’, in Infrastructures for Virtual Enterprises (PRO-VE’99), L.M. Camarinha-Matos, H. Afsarmanesh (Eds.), Kluwer Academic Publishers, October 1999. |
|
[CAR00] |
Cardoso, H.L.; Oliveira, E., ‘A Platforme for Electronic Commerce with Adaptative Agents’ , NIAD&R-LIACC, FEUP, 2000. |
|
[DAV83] |
Davis, R.; Smith, R.J., ‘Negotiation as a Metaphor for Distributed Problem-solving’, Artificial Intelligence, 20(1), pp. 63-109, 1983. |
|
[EDI98] |
UN/EDIFACT (EWG) [http://www.edifact-wg.org/]. |
|
[EDW99] |
Edwards, W.K., ‘Core Jini’, Prentice-Hall, 1999, ISBN 0-130-14469-X. |
|
[EIL94] |
Enterprise Integration Laboratory, Department of Industrial Engineering, University of Toronto [http://www.eil.utoronto.ca/eil.html]. |
|
[FIN97] |
Finin, T:; Labrou, Y., ‘A Proposal for a new KQML Specification’, Computer Science and Electrical Engineering Department, University of Maryland Baltimore County, Baltimore, TR CS-97-03, February 1997. [http://www.cs.umbc.edu/kqml]. |
|
[FIS96] |
Fischer, K.; Muller, J.; Heimig, I.; Scheer, A.-W., ‘Intelligent Agents in Virtual Enterprises’, Proceedings of the First International Conference on Practical Application of Intelligent Agents and Multi Agent Technology. London, UK, April 1996. |
|
[FLA97] |
Flanagan, D., ‘Java In a Nutshell’, O’Reilly & Associates, Inc, 2nd edition, 1997, ISBN 1-56592-262-X. |
|
[FRE99] |
Freeman, E.; Hupfer, S.; Arnold, K., ‘JavaSpaces Principles, Patterns, and
Practice (The Jini Technology Series)’, Addison-Wesley, 1999, ISBN
0-201-30955-6. |
|
[GEL85] |
Gelernter, D., ‘Generative Communication in Linda’, ACM Transactions on Programming Languages and Systems, Vol.7, No.1 (January, 1985) pp 80-112. |
|
[JÄGE98] |
Jägers, H.P.M.; Jansen, W; Steenbakkers,
G.C.A., ‘Wat zijn virtuele
organisties?:Op zoek naar definities en kenmerken’, in Informatie en
informatiebeleid, spring no.1, p.61-67, 1998 [Holandês]. (Citado em [BUL98]) |
|
[JAV9xA] |
The Source for Java™ [http://java.sun.com/]. |
|
[JAV9xB] |
Security Features Overview [http://java.sun.com/docs/books/tutorial/security1.2/overview/index.html]. |
|
[JAV9xC] |
An Overview of RMI Applications [http://java.sun.com/docs/books/tutorial/rmi/overview.html]. |
|
[JEN96] |
Jennings, N.R.; Farantin, P., Jonhson, M.J.; O’Brien, P.; Wiegand, M.E., ‘Using Intelligent Agents to Manage Business Process’, Proceedings of the First International Conference on the Practical Application of Intelligent Agents and multi Agent Technology, London, UK, April 1996. |
|
[JEN98] |
Jennings, N.R.; Sycara, K.; Wooldridge, M., ‘A Roadmap of Agent Research and Development’, Autonomous Agents and Multi-Agent Systems, Vol.1, No.1, pp.7-38. |
|
[JIN99] |
FAQ for JINI-USERS Mailing List [http://www.artima.com/jini/faq.html]. |
|
[KATZ99] |
Katzy, B.; Obozinsky, V., ‘Designing the virtual enterprise’, Proceedings of ICE’99. 5th Int. Conf. On Concurrent Enterprising, The Hague, Netherlands, March 15-17, 1999.(Citado em [CAM99A]) |
|
[KIF98] |
‘Knowledge Interchange Format’, draft proposed American National Standard NCITS.T2/98-004 [http://meta2.stanford.edu/kif/dpans.html]. |
|
[MOWS94] |
Mowshowitz, A., ‘Virtual Organisation: A Vision of Management in the Information Age’,
in The Information Society vol.10, p.267-288, United-Kingdom, 1994. (Citado em [BUL98]) |
|
[NIIIP94] |
The National Industrial Information Infrastructure Protocols (NIIIP) Reference Manual [http://www.niiip.org/]. |
|
[OLI00] |
Oliveira, E.; Rocha, A.P., ‘Agents advanced features for negotiation in Electronic Commerce and Virtual Organisations formation process’, Agent Mediated Electronic Commerce - an European Perspective, Springer Verlag, Eds. F. Dgnum, C. Sierra, Lecture Notes in Artificial Intelligence (LNAI) No.1991, 2000. |
|
[OLI99] |
Oliveira, E.; Fonseca, J.M.; Steiger-Gração, A., ‘Multi-criteria Negotiation on Multi-Agent Systems’, Proceedings of the First International Workshop of Central and Eastern Europe on Multi-Agent Systems, St. Petersburg, Russia, June 1999. |
|
[OMG89] |
Object Management Group [http://www.corba.org/]. |
|
[RAB96] |
Rabelo, R.; Camarinha-Matos, L.M., Towards Agile Scheduling in Extended Enterprise, Balanced Automation Systems II: Implementation Challenges for Anthropocentric Manufacturing, Chapman & Hall, London, June 1996. |
|
[REIS00] |
Reis, L.P.; Oliveira, E.; ‘A Language for Specifying Complete Timetabling Problems’, Proceedings of the Third International Conference on the Practice and Theory of Automated Timetabling, 2000. |
|
[ROC00] |
Rocha, A.P.; Oliveira, E., ‘Adaptative multi-issue negotiation protocol for Electronic Commerce’, Proceedings of the Fifth International Conference on the Practical Application of Intelligent Agents and Multi-Agent Technology, Manchester, UK, April 2000. |
|
[ROC98] |
Rocha, A.P.; Oliveira,
E., ‘Electronic Commerce: a
technological perspective’, NIAD&R-LIACC, FEUP, 1998, in ‘O Futuro da
Internet’, Edições Centro Atlântico, 1999, págs 127-138, ISBN 972-8426-08-9. |
|
[ROC99] |
Rocha, A.P.; Oliveira, E., ‘An Electronic Market Architecture for the Formation of Virtual Enterprises’, NIAD&R-LIACC, FEUP, 1999. |
|
[SHM99] |
Shmeil, M.A.H., ARTOR –
Sistemas Multi-agente na Modelação da Estrutura e Relações de Contratação de
Organizações, Tese de doutoramento, FEUP, Junho 1999. |
|
[SIEB98] |
Sieber, P. and Griese, J., ‘Organisation Virtualness: Proceedings of
the VoNet-Workshop’, Simowa Verlag Bern, April 1998. (Citado em [BUL98]) |
|
[SUT98] |
Sutton, R.S.; Barto, A.G., ‘Reinforcement Learning: An Introduction’, MIT Press, Cambridge, MA, 1998. |
|
[THAM9xA] |
Tham, K.D., CIM-OSA: Enterprise Modelling, EIL, University of Toronto, Canadá. [http://www.eil.utoronto.ca/entmethod/cimosa/cim.html]. |
|
[THAM9xB] |
Tham, K.D., PERA: Enterprise Modelling, EIL, University of Toronto, Canadá. [http://www.eil.utoronto.ca/entmethod/pera/pera.html]. |
|
[TOV9x] |
TOVE Ontologies, Enterprise Integration Laboratory, Department of Industrial Engineering, University of Toronto, Canadá. [http://www.eil.utoronto.ca/tove/toveont.html]. |
|
[UNI86] |
UNINOVA [http://www.uninova.pt/]. |
[1] Projecto de cooperação financiado pela Comissão Europeia e envolvendo parceiros europeus e latino-americanos.